HBase系列-HBase基本概念
内容整理自:
- Github仓库: God-Of-BigData/HBase系列
基本概念
数据在 HBase 中逻辑意义上的排布:
| Row-Key | Value(CF、Qualifier、Version) |
|---|---|
| 1 | info{‘姓’: ‘张’,’名’:’三’} pwd{‘密码’: ‘111’} |
| 2 | Info{‘姓’: ‘李’,’名’:’四’} pwd{‘密码’: ‘222’} |
数据在 HBase 中物理上的排布:
| Row-Key | CF:Column-Key | 时间戳 | Cell Value |
|---|---|---|---|
| 1 | info:ln | 123456789 | 张 |
| 1 | info:fn | 123456789 | 三 |
| 2 | info:ln | 123456789 | 李 |
| 2 | info:fn | 123456789 | 四 |
Row key(行键)
Row Key是用来检索记录的主键,访问HBase中的数据只能通过Rowkey、Rowkey的range或者全表扫描三种方式,全表扫描性能太差Row Key可以是任意字符串,存储时按照字典序进行排序,需要注意:- 因为字典序对 Int 排序的结果是 1,10,100,11,18,19,2,20,21,…,9,91,…,99。如果你使用整型的字符串作为行键,那么为了保持整型的自然序,行键必须用 0 作左填充
- 行的一次读写操作时原子性的 (不论一次读写多少列)
Column Family(列族)
HBase 表中的每个列,都归属于某个列族。列族是表的 Schema 的一部分,所以列族需要在创建表时进行定义。列族的所有列都以列族名作为前缀,例如 info:ln,info:fn 都属于 info 这个列族
Column Qualifier(列限定符)
可以理解为是具体的列名,例如 info:ln,info:fn 都属于 info 这个列族,它们的列限定符分别是 ln 和 fn。需要注意的是列限定符不是表 Schema 的一部分,你可以在插入数据的过程中动态创建列
Column(列)
HBase 中的列由列族和列限定符组成,它们由 :(冒号) 进行分隔,即一个完整的列名应该表述为 列族名 :列限定符
Cell
HBase 中通过 row key 和 column 确定的为一个存储单元称为 Cell,是行,列族和列限定符的组合,并包含值和时间戳
TimeStamp(时间戳)
每个 Cell 都保存着同一份数据的多个版本。版本通过时间戳来索引,时间戳的类型是 64 位整型,时间戳可以由 HBase 在数据写入时自动赋值,也可以由客户显式指定。每个 Cell 中,不同版本的数据按照时间戳倒序排列,即最新的数据排在最前面
Rowkey设计原则
打散Rowkey
HBase中的行是按照RowKey字典序排序的。这对Scan操作非常友好,因为RowKey相近的行总是存储在相近的位置,顺序读的效率比随机读要高。但是,如果大量的读写操作总是集中在某个RowKey范围,那么就会造成Region热点,拖累RegionServer的性能。因此,要适当地将RowKey打散
控制RowKey长度
- 在HBase的底层存储HFile中,RowKey是KeyValue结构中的一个域。假设RowKey长度100B,那么1000万条数据中,只算RowKey就占用掉将近1G空间,会影响HFile的存储效率
- HBase中设计有MemStore和BlockCache,分别对应列族/Store级别的写入缓存,和RegionServer级别的读取缓存。如果RowKey过长,缓存中存储数据的密度就会降低,影响数据落地或查询效率
保证RowKey唯一性
存储结构
Regions
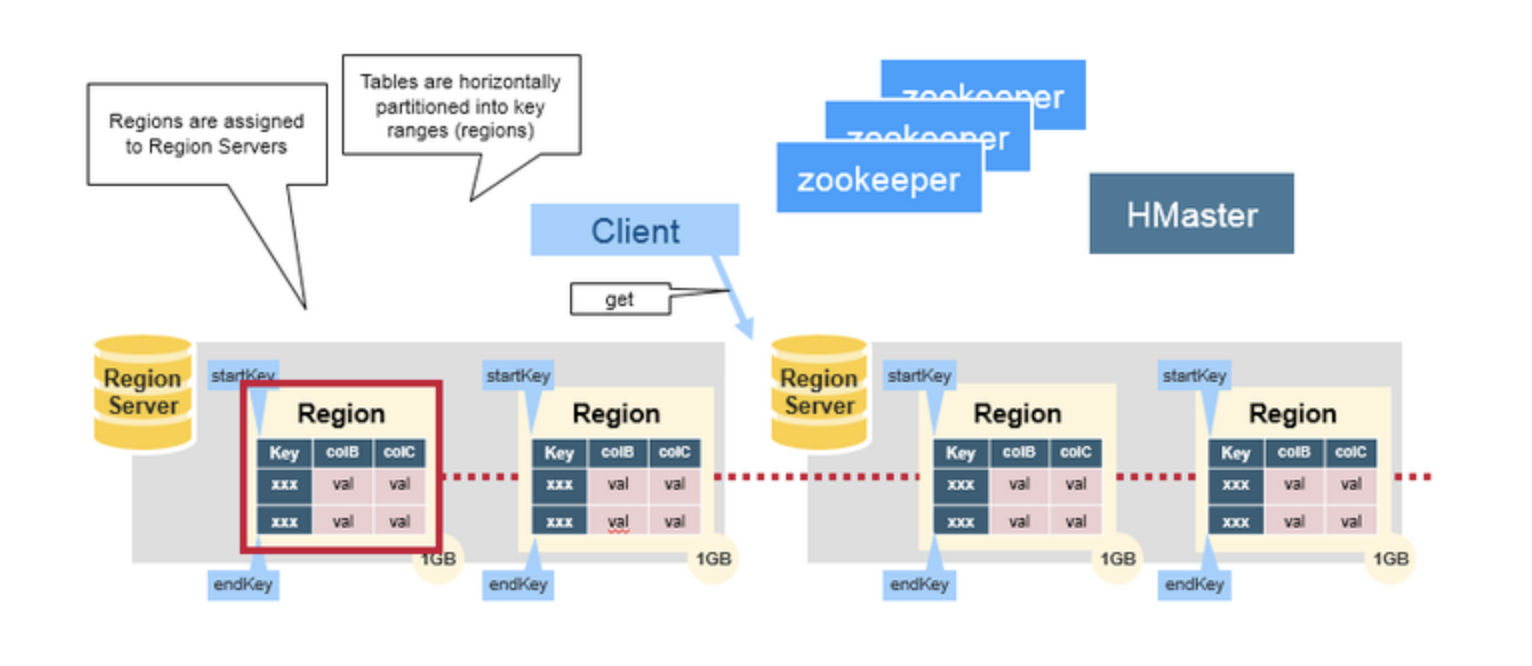
- HBase Table 中的所有行按照
Row Key的字典序排列。HBase Tables 通过行键的范围 (row key range) 被水平切分成多个Region, 一个Region包含了在 start key 和 end key 之间的所有行
每个表一开始只有一个
Region,随着数据不断增加,Region会不断增大,当增大到一个阀值的时候,Region就会等分为两个新的Region。当 Table 中的行不断增多,就会有越来越多的RegionRegion是 HBase 中分布式存储和负载均衡的最小单元。这意味着不同的Region可以分布在不同的Region Server上。但一个Region是不会拆分到多个 Server 上的
Region Server
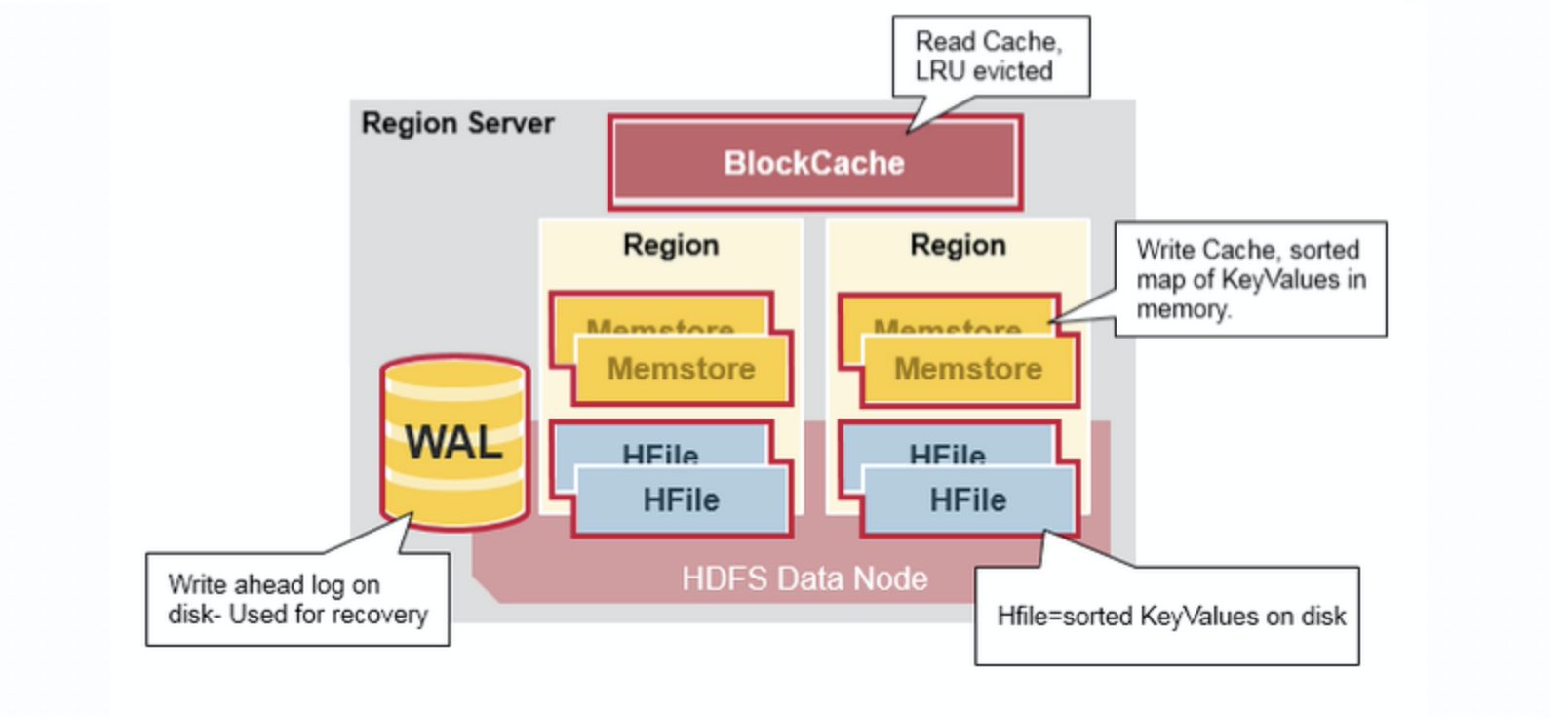
Region Server 运行在 HDFS 的 DataNode 上。它具有以下组件:
- WAL(Write Ahead Log,预写日志):用于存储尚未进持久化存储的数据记录,以便在发生故障时进行恢复。
- BlockCache:读缓存。它将频繁读取的数据存储在内存中,如果存储不足,它将按照
最近最少使用原则清除多余的数据。 - MemStore:写缓存。它存储尚未写入磁盘的新数据,并会在数据写入磁盘之前对其进行排序。每个 Region 上的每个列族都有一个 MemStore。
- StoreFile :StoreFile底层是
HFile,HFile是Hadoop的二进制格式文件, 将行数据按照 Key\Values 的形式存储在文件系统上
Region Server 存取一个子表时,会创建一个 Region 对象,然后对表的每个列族创建一个 Store 实例,每个 Store 会有 0 个或多个 StoreFile 与之对应,每个 StoreFile 则对应一个 HFile,HFile 就是实际存储在 HDFS 上的文件
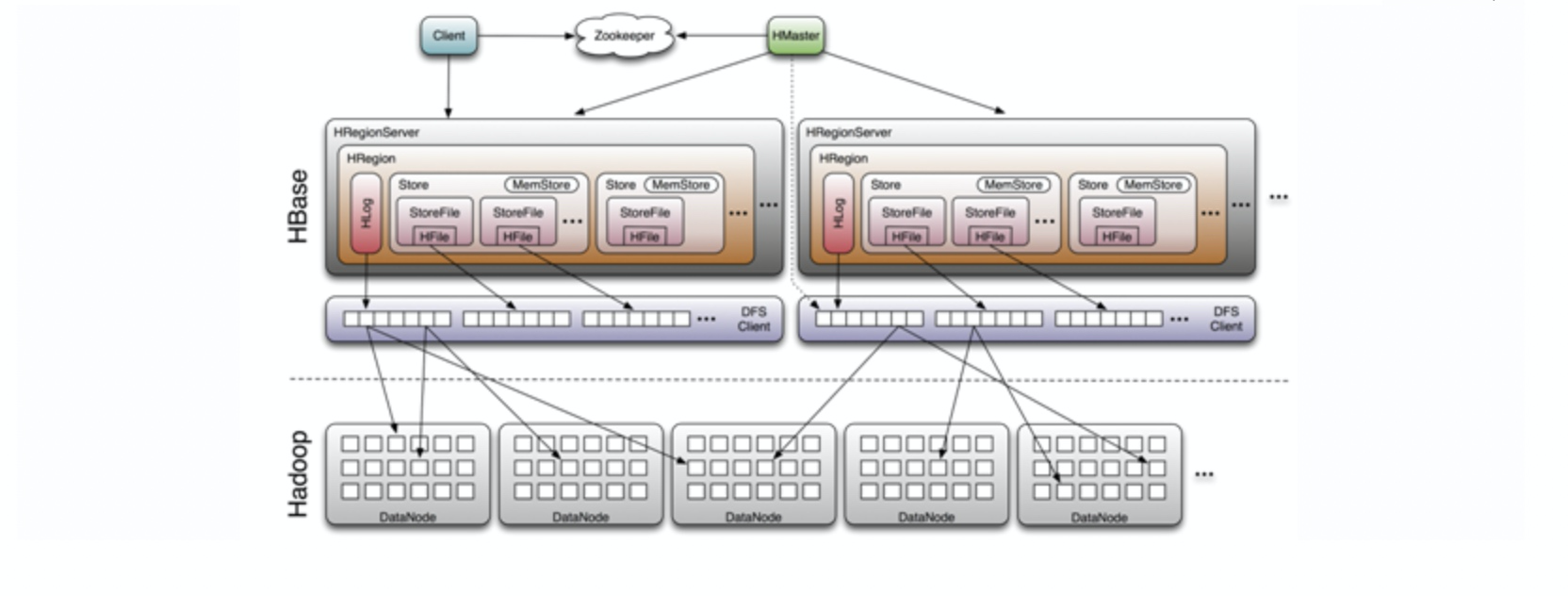
系统架构
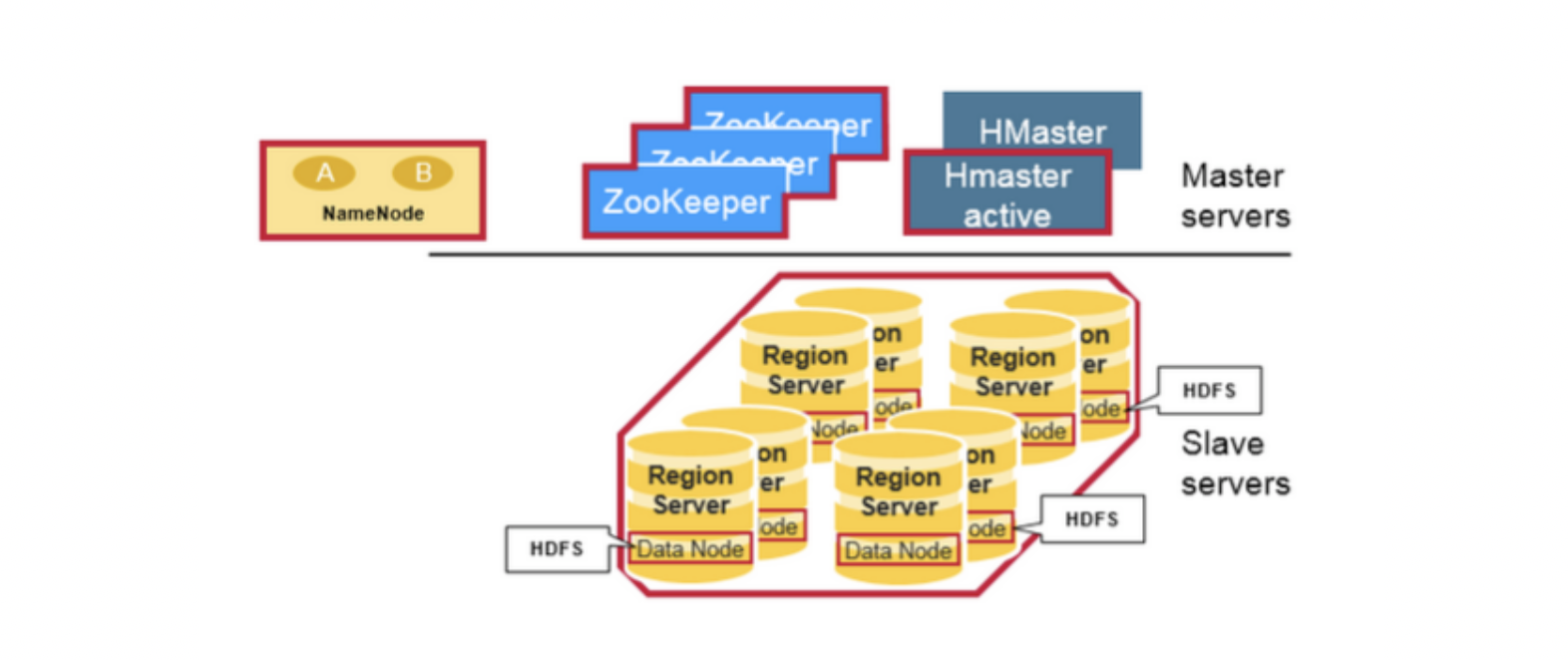
HBase 系统遵循 Master/Salve 架构,由三种不同类型的组件组成:
Zookeeper
- 保证任何时候,集群中只有一个 Master;
- 存贮所有 Region 的寻址入口;
- 实时监控 Region Server 的状态,将 Region Server 的上线和下线信息实时通知给 Master;
- 存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family 等信息。
Master
- 为 Region Server 分配 Region ;
- 负责 Region Server 的负载均衡 ;
- 发现失效的 Region Server 并重新分配其上的 Region;
- GFS 上的垃圾文件回收;
- 处理 Schema 的更新请求。
Region Server
- Region Server 负责维护 Master 分配给它的 Region ,并处理发送到 Region 上的 IO 请求;
- Region Server 负责切分在运行过程中变得过大的 Region。
组件间的协作
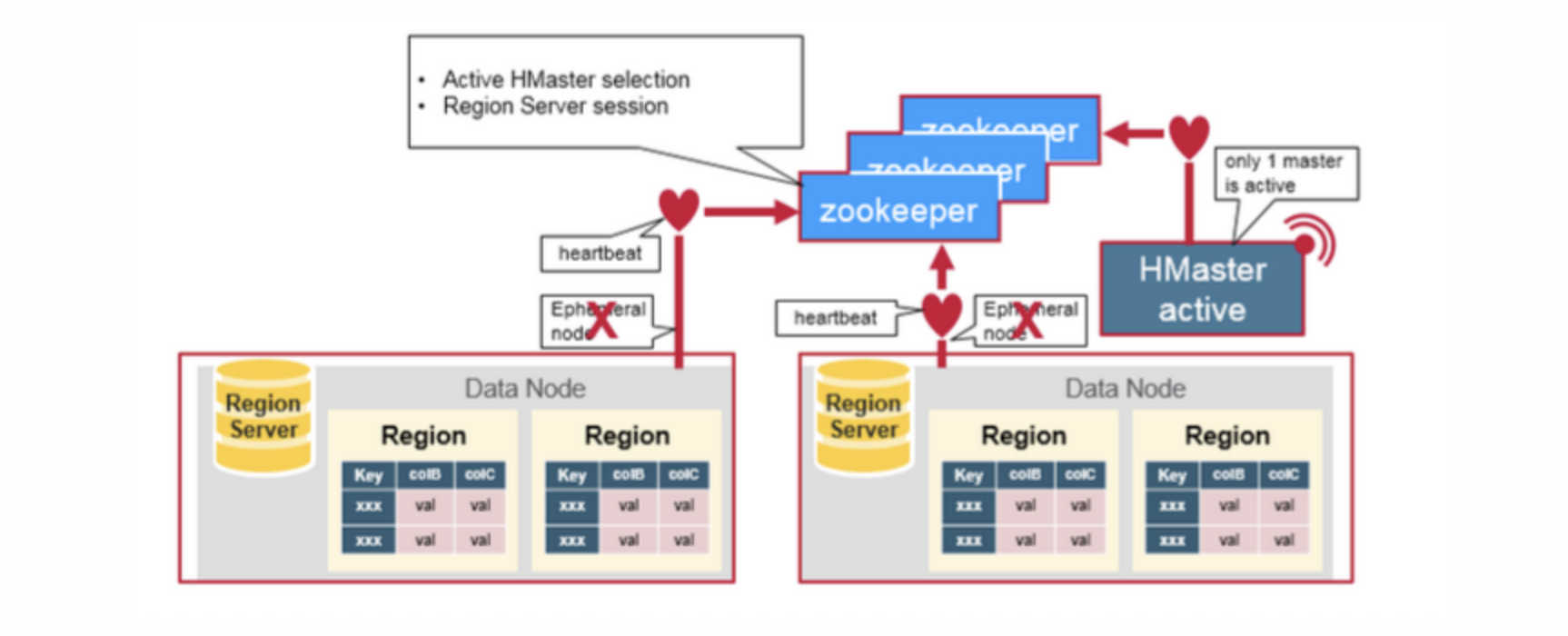
HBase 使用 ZooKeeper 作为分布式协调服务来维护集群中的服务器状态。 Zookeeper 负责维护可用服务列表,并提供服务故障通知等服务:
- 每个 Region Server 都会在 ZooKeeper 上创建一个临时节点,Master 通过 Zookeeper 的 Watcher 机制对节点进行监控,从而可以发现新加入的 Region Server 或故障退出的 Region Server;
- 所有 Masters 会竞争性地在 Zookeeper 上创建同一个临时节点,由于 Zookeeper 只能有一个同名节点,所以必然只有一个 Master 能够创建成功,此时该 Master 就是主 Master,主 Master 会定期向 Zookeeper 发送心跳。备用 Masters 则通过 Watcher 机制对主 HMaster 所在节点进行监听;
- 如果主 Master 未能定时发送心跳,则其持有的 Zookeeper 会话会过期,相应的临时节点也会被删除,这会触发定义在该节点上的 Watcher 事件,使得备用的 Master Servers 得到通知。所有备用的 Master Servers 在接到通知后,会再次去竞争性地创建临时节点,完成主 Master 的选举