Flink基础-DataStream编程 流处理API衍变(对比Storm)
Storm的API抽象层次更低点,相当于是面向操作的,通过代码直接自己自定义构造DAG
1 2 3 4 5 TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout" , new RandomSentenceSpout(), 5 ); builder.setBolt("split" , new SplitSentence(), 8 ).shuffleGrouping("spout" ); builder.setBolt("count" , new WordCount(), 12 ).fieldsGrouping("split" , new Fields("word" ));
Flink相当于是面向数据的,通过API, 也就是一系列算子对数据进行一系列转换计算,由Flink底层自己构建生成DAG,所以相对来说抽象层次更高点
基本使用 1 2 3 4 5 6 7 8 9 10 StreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment();DataStream text = env.readTextFile ("input" );DataStream <Tuple2 <String , Integer >> counts = text.flatMap(new Tokenizer ()).keyBy(0 ).sum(1 );counts.writeAsText("output" ); env.execute("Streaming WordCount" );
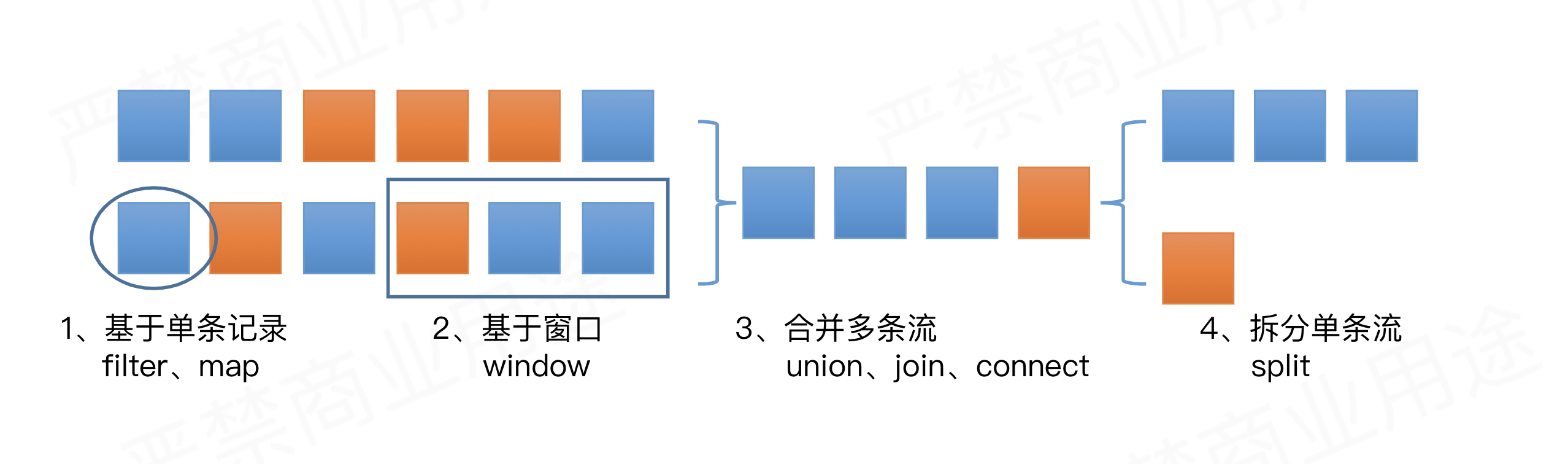
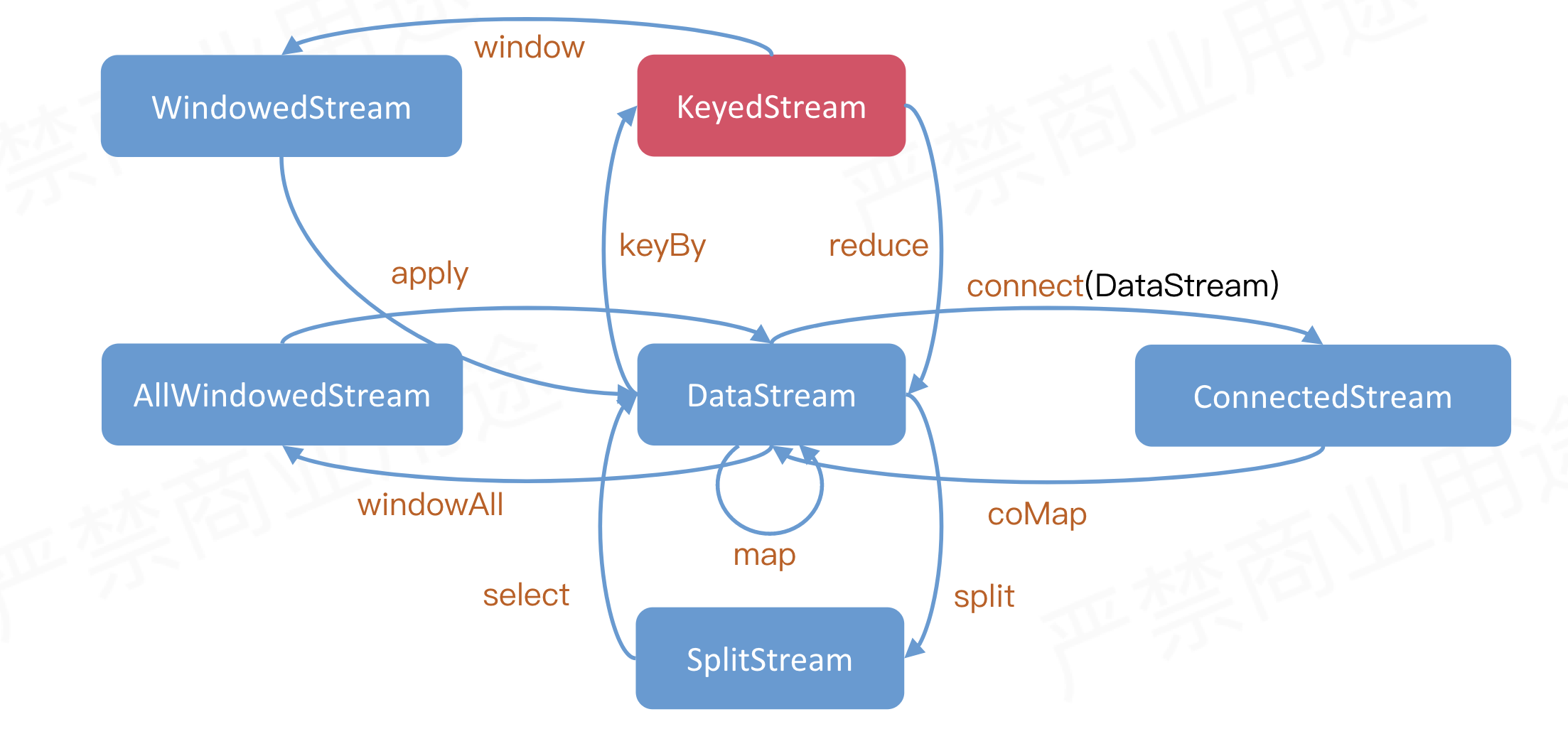
操作概览
DataStream基本转换
物理分组方法 只有进行分组后才能调用reduce/sum等算子进行统计计算
类型
描述
keyBy()
最常用的按key类型发送,key的类型数量往往远大于算子并发实例数
global()
全部发往第一个task
broadcast()
广播,适用于数据量小的情况
forward()
上下游并发度一致时一对一发送
shuffle()
随机均匀分配
rebalance()
Round-Robin(轮流分配)
rescale()
Local Round-Robin(本地轮流分配)
partitionCustomer()
自定义单播()
Author:
EgoSay
Permalink:
http://cjwdream.top/2020/03/30/Flink-DataStream/
License:
Copyright (c) 2019 CC-BY-NC-4.0 LICENSE