分布式一致性哈希
内容来自
- 极客时间专栏:《分布式技术原理与算法解析》
- 5分钟理解一致性哈希算法
数据分布设计原则
在分布式数据存储系统中,存储方案选型时,通常会考虑数据均匀、数据稳定和节点异构性这三个维度。
从数据均匀的维度考虑,主要包括两个方面:
- 不同存储节点中存储的数据要尽量均衡,避免让某一个或某几个节点存储压力过大,而其他节点却几乎没什么数据。
- 另外,用户访问也要做到均衡,避免出现某一个或某几个节点的访问量很大,但其他节点却无人问津的情况。
从数据稳定的维度考虑,当存储节点出现故障需要移除或者扩增时,数据按照分布规则得到的结果应该尽量保持稳定,不要出现大范围的数据迁移
从节点异构性的维度考虑,不同存储节点的硬件配置可能差别很大,导致性能差别就很大,但是分到的数据量、用户访问量都差不多,这本质就是一种不均衡。所以,一个好的数据分布算法应该考虑节点异构性
一致性哈希
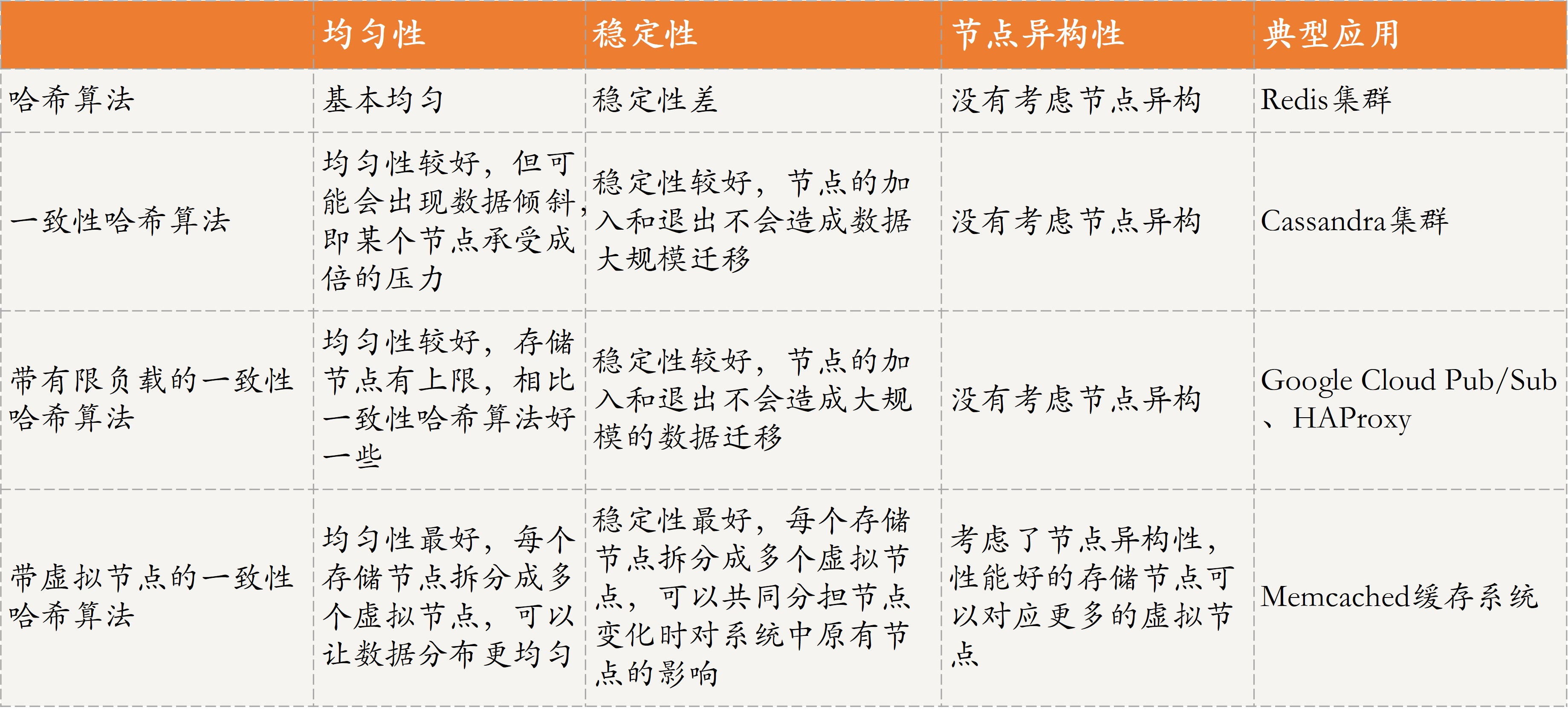
一致性哈希是指将存储节点和数据都映射到一个首尾相连的哈希环上,存储节点可以根据 IP 地址进行哈希(相当于两次哈希),数据通常通过顺时针方向寻找的方式,来确定自己所属的存储节点,即从数据映射在环上的位置开始,顺时针方向找到的第一个存储节点。目前,Cassandra 就使用了一致性哈希方法
在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。比如 Node2节点宕机后,干扰的只有前面的数据(原数据被保存到顺时针的下一个服务器节点Node3),而不会干扰到其他的数据。
这种方法虽然提升了稳定性,但随之而来的均匀性问题也比较明显,有节点退出后,该节点的后继节点需要承担该节点的所有负载,如果后继节点承受不住,便会出现节点故障,导致后继节点的后继节点也面临同样的问题。Google 在 2017 年提出了带有限负载的一致性哈希算法,就对这个问题做了一些优化
带有限负载的一致性哈希
带有限负载的一致性哈希方法的核心原理是,给每个存储节点设置了一个存储上限值来控制存储节点添加或移除造成的数据不均匀。当数据按照一致性哈希算法找到相应的存储节点时,要先判断该存储节点是否达到了存储上限;如果已经达到了上限,则需要继续寻找该存储节点顺时针方向之后的节点进行存储
该算法的详细内容,参考“Consistent Hashing with Bounded Loads”这篇论文
带有限负载的一致性哈希方法比较适合同类型节点、节点规模会发生变化的场景。目前,在 Google Cloud Pub/Sub、HAProxy 中已经实现该方法,应用于 Google、Vimeo 等公司的负载均衡项目中。
带虚拟节点的一致性哈希
一致性哈希、带有限负载的一致性哈希,都没有考虑节点异构性的问题。如果存储节点的性能好坏不一,数据分布方案还按照这些方法的话,其实还是没做到数据的均匀分布.
带虚拟节点的一致性哈希方法,核心思想是根据每个节点的性能,为每个节点划分不同数量的虚拟节点,并将这些虚拟节点映射到哈希环中,然后再按照一致性哈希算法进行数据映射和存储
带虚拟节点的一致性哈希方法比较适合异构节点、节点规模会发生变化的场景。目前 Memcached 缓存系统实现了该方法
总结拓展
几种哈希算法的总结
数据分片和数据分区,有何区别?
数据分区是从数据存储块的维度进行划分,不同的分区物理上归属于不同的节点。比如,现在有 2 个节点 Node1 和 Node2,2 个数据分区 Partition1 和 Partition2,Partition1 属于 Node1、Partition2 属于 Node2
数据分片是从数据的维度进行划分,是指将一个数据集合按照一定的方式划分为多个数据子集,不同的数据子集存在不同的存储块上,而这些存储块可以在不同的节点上,也可以在同一节点上