分布式计算
内容来自
- 极客时间专栏:《分布式技术原理与算法解析》
MapReduce计算模式(分冶法)
分而冶之思想
简称分冶法,就是将一个复杂的、难以直接解决的大问题,分割成一些规模较小的、可以比较简单的或直接求解的子问题,这些子问题之间相互独立且与原问题形式相同,递归地求解这些子问题,然后将子问题的解合并得到原问题的解
计算流程
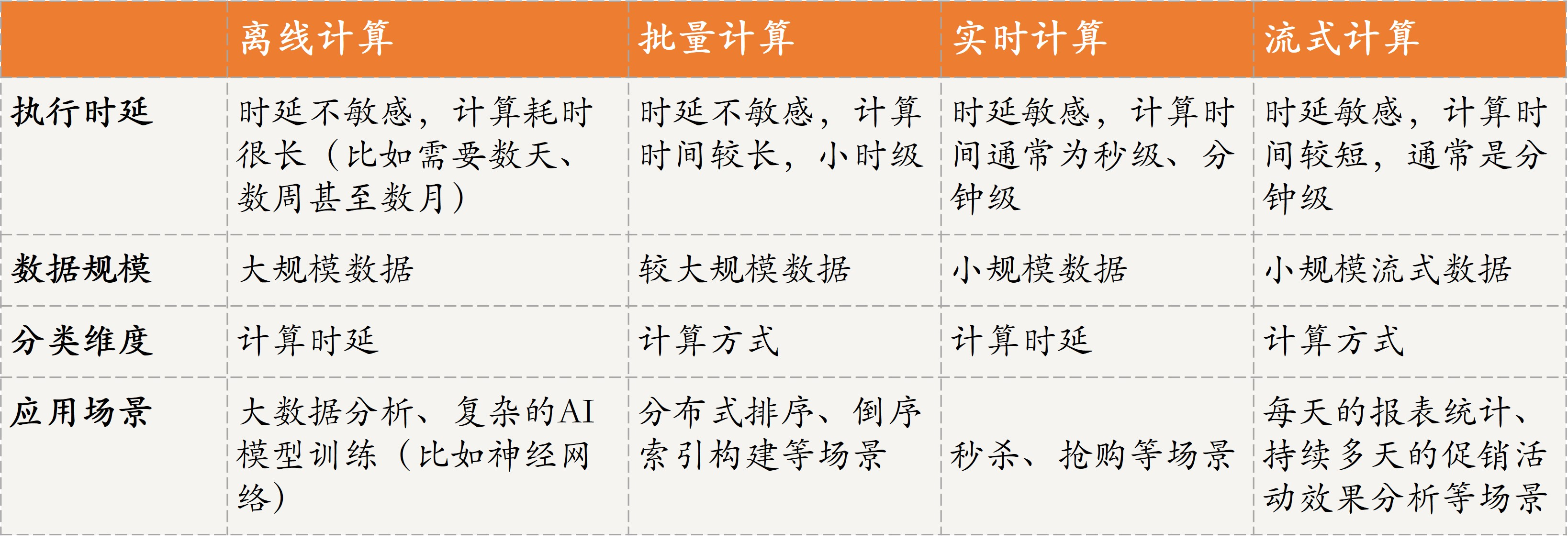
整个 MapReduce 的工作流程主要可以概括为 5 个阶段,即:Input(输入)、Splitting(拆分)、Mapping(映射)、Reducing(化简)以及 Final Result(输出)
Fork-Join 计算模式
Fork-Join 是 Java 等语言或库提供的原生多线程并行处理框架,采用线程级的分而治之计算模式。它充分利用多核 CPU 的优势,以递归的方式把一个任务拆分成多个“小任务”,把多个“小任务”放到多个处理器上并行执行,即 Fork 操作。当多个“小任务”执行完成之后,再将这些执行结果合并起来即可得到原始任务的结果,即 Join 操作
Fork-Join 不能大规模扩展,只适用于在单个 Java 虚拟机上运行,多个小任务虽然运行在不同的处理器上,但可以相互通信,甚至一个线程可以“窃取”其他线程上的子任务
Stream计算模式
MapReduce 模式下任务运行完成之后,整个任务进程就结束了,属于短任务模式。但任务进程的启动和停止是一件很耗时的事儿,因此针对流数据的处理,对处理延时要求很高的实时性任务,往往利用的就是 Stream流计算模型
Stream 工作原理
流计算强调的是实时性,数据一旦产生就会被立即处理,当一条数据被处理完成后,会序列化存储到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理,而不是像 MapReduce 那样,等到缓存写满才开始处理、传输。为了保证数据的实时性,在流计算中,不会存储任何数据,就像水流一样滚滚向前
计算步骤
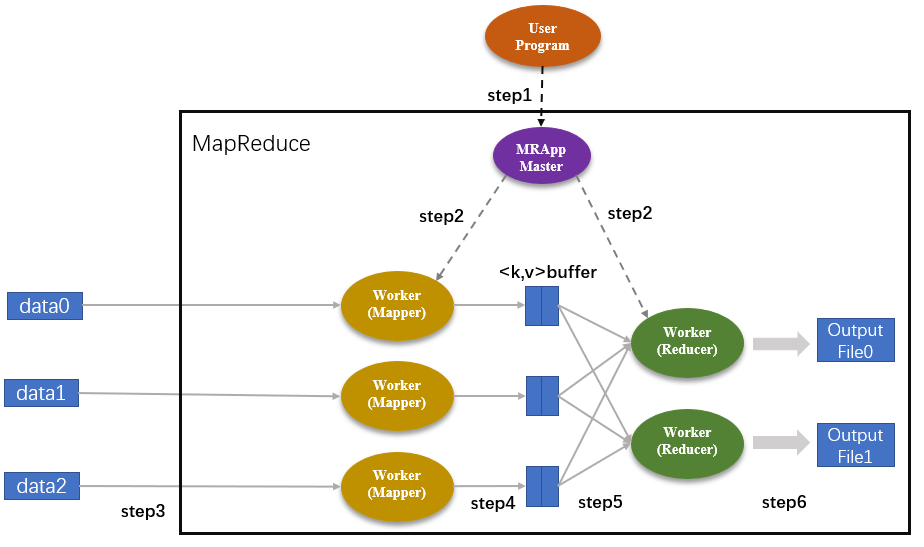
- 提交流式计算作业:对于流式计算作业,必须预先定义计算逻辑,且提交后在运行期间不可更改逻辑,只能重新提交运行
- 加载流式数据进行流计算:流式计算作业一旦启动将一直处于等待事件触发的状态,一旦有小批量数据进入,系统会立刻执行计算逻辑并迅速得到结果
- 持续输出计算结果:在得到小批量数据的计算结果后,可以立刻将结果数据写入在线 / 批量系统,无需等待整体数据的计算结果,以进一步做到实时计算结果的实时展现
Actor计算模式
Actor 模型,代表一种分布式并行计算模型。这种模型有自己的一套规则,规定了 Actor 的内部计算逻辑,以及多个 Actor 之间的通信规则。在 Actor 模型里,每个 Actor 相当于系统中的一个组件,都是基本的计算单元
Actor 模型的三要素是状态、行为和消息,有一个很流行的等式:Actor 模型 =(状态 + 行为)+ 消息
Actor 工作流程
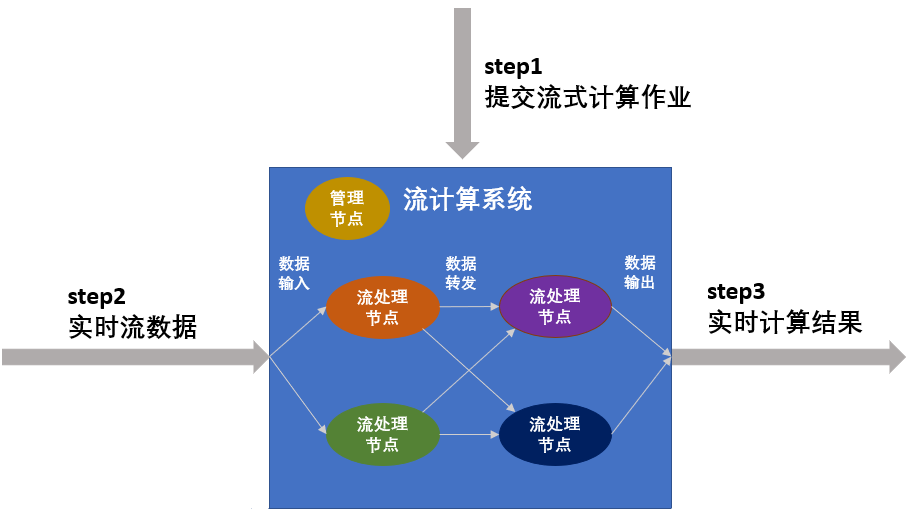
当 Actor A 和 Actor B 需要执行 Actor C 中的 Function 逻辑时,Actor A 和 Actor B 会将消息发送给 Actor C, Actor C 的消息队列存储着 Actor A 和 Actor B 的消息,然后根据消息的先后顺序,执行 Function 即可
Actor 优缺点分析
优点
- 实现了更高级的抽象。Actor 与 OOP 对象类似,封装了状态和行为。但是,Actor 之间是异步通信的,多个 Actor 可以独立运行且不会被干扰,解决了 OOP 存在的竞争问题。
- 非阻塞性。在 Actor 模型中,Actor 之间是异步通信的,所以当一个 Actor 发送信息给另外一个 Actor 之后,无需等待响应,发送完信息之后可以在本地继续运行其他任务。也就是说,Actor 模型通过引入消息传递机制,从而避免了阻塞。
- 无需使用锁。Actor 从 MailBox 中一次只能读取一个消息,也就是说,Actor 内部只能同时处理一个消息,是一个天然的互斥锁,所以无需额外对代码加锁。
- 并发度高。每个 Actor 只需处理本地 MailBox 的消息,因此多个 Actor 可以并行地工作,从而提高整个分布式系统的并行处理能力。
- 易扩展。每个 Actor 都可以创建多个 Actor,从而减轻单个 Actor 的工作负载。当本地 Actor 处理不过来的时候,可以在远程节点上启动 Actor 然后转发消息过去
缺点
- Actor 提供了模块和封装,但缺少继承和分层,这使得即使多个 Actor 之间有公共逻辑或代码部分,都必须在每个 Actor 中重写这部分代码,也就是说重用性小,业务逻辑的改变会导致整体代码的重写
- Actor 可以动态创建多个 Actor,使得整个 Actor 模型的行为不断变化,因此在工程中不易实现 Actor 模型。此外,增加 Actor 的同时,也会增加系统开销。
- Actor 模型不适用于对消息处理顺序有严格要求的系统。因为在 Actor 模型中,消息均为异步消息,无法确定每个消息的执行顺序。虽然可以通过阻塞 Actor 去解决顺序问题,但显然,会严重影响 Actor 模型的任务处理效率
Actor 模型的应用
- Akka
- Quasar (Java)
- Erlang/OTP
Actor模型总结: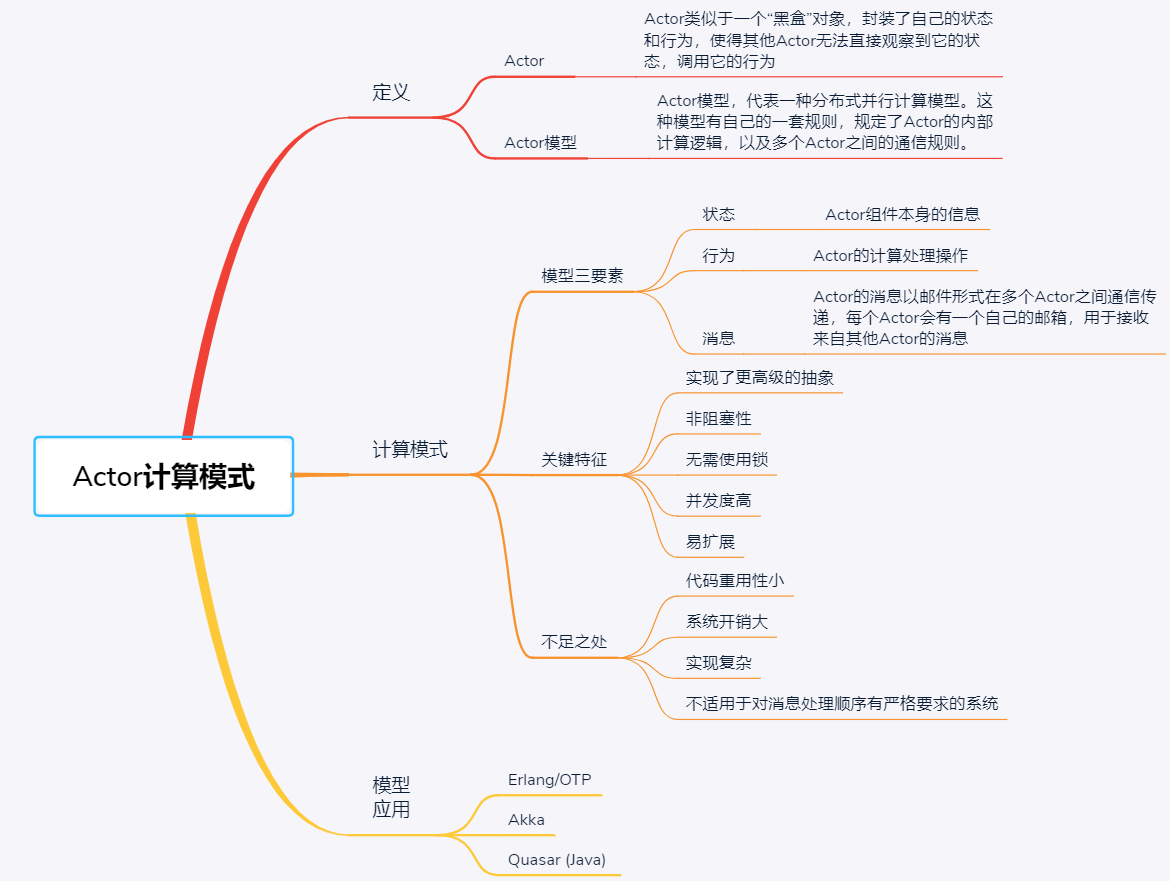
Pipeline流水线计算模式
计算机中的流水线(Pipeline)技术是一种将每条指令拆分为多个步骤,多条指令的不同步骤重叠操作,从而实现几条指令并行处理的技术。现代 CPU 指令采用了流水线设计,将一条 CPU 指令分为取指(IF)、译码(ID)、执行(EX)、访存(MEM)、回写(WB)五级流水线来执行。在分布式领域中,流水线计算模式也类似,它是将一个大任务拆分为多个步骤执行,不同的步骤可以采用不同的进程执行
计算流程
以机器学习中的数据预处理为例,假设现在有 5 个样本数据,每个样本数据进行数据预处理的流程,包括数据去重、数据缺失值处理、数据归一化 3 个步骤,且需要按照顺序执行。也就是说,数据预处理这个任务可拆分为数据去重—> 数据缺失值处理—> 数据归一化 3 个子任务。如果现在有 3 个节点,节点 1 执行数据去重,节点 2 执行数据缺失值处理,节点 3 执行数据归一化。那么,节点 1 处理完样本 1 的数据,将处理后的数据发送节点 2 后,则节点 1 可以继续处理样本 2 的数据,同时节点 2 处理样本 1 的数据,以此类推,就实现了多任务的并行执行
流水线计算模式应用
- 机器学习流水线任务,比如TensorFlow
- Apache Beam(没具体研究过,看介绍是基于流水线处理思想)
总结拓展
流计算和批量计算的区别

流水线模式和 MapReduce 模式中,都有将大任务拆分为多个子任务,两者的区别是什么?
- MapReduce 以任务为粒度,将大的任务划分成多个小任务,每个任务都需要执行完整的、相同的步骤,同一任务能被并行执行,可以说是任务并行的一种计算模式;
- 而流水线计算模式以步骤为粒度,一个任务拆分为多个步骤,每个步骤执行的是不同的逻辑,多个同类型任务通过步骤重叠以实现不同任务的并行计算,可说是数据并行的一种模式
此外,它们的子任务(步骤)间的关系不同:
- 在 MapReduce 中,各个子任务可以独立执行,互不干扰,多个子任务执行完后,进行结果合并得到整个任务的结果,因此要求子任务之间是没有依赖关系的;
- 在流水线模式中,多个子任务之间是具有依赖关系的,前一个子任务的输出是后一个子任务的输入。
综合来讲,MapReduce 计算模式适合任务并行的场景,而流水线计算模式适合同类型任务数据并行处理的场景
离线计算和批量计算、实时计算和流式计算之间的关系