分布式选举算法
内容来自
选举(election)是分布式系统实践中常见的问题,通过打破节点间的对等关系,选得的leader(或叫master、coordinator)有助于实现事务原子性、提升决议效率。多数派(quorum)的思路帮助我们在网络分化的情况下达成决议一致性,在leader选举的场景下帮助我们选出唯一leader。租约(lease)中心思想是每次租约时长内只有一个节点获得租约成为leader、到期后必须重新颁发租约,确保了一个时刻最多只有一个leader,避免只使用心跳机制时因为网络拥塞或瞬断而产生双主的问题
Bully算法(选举)
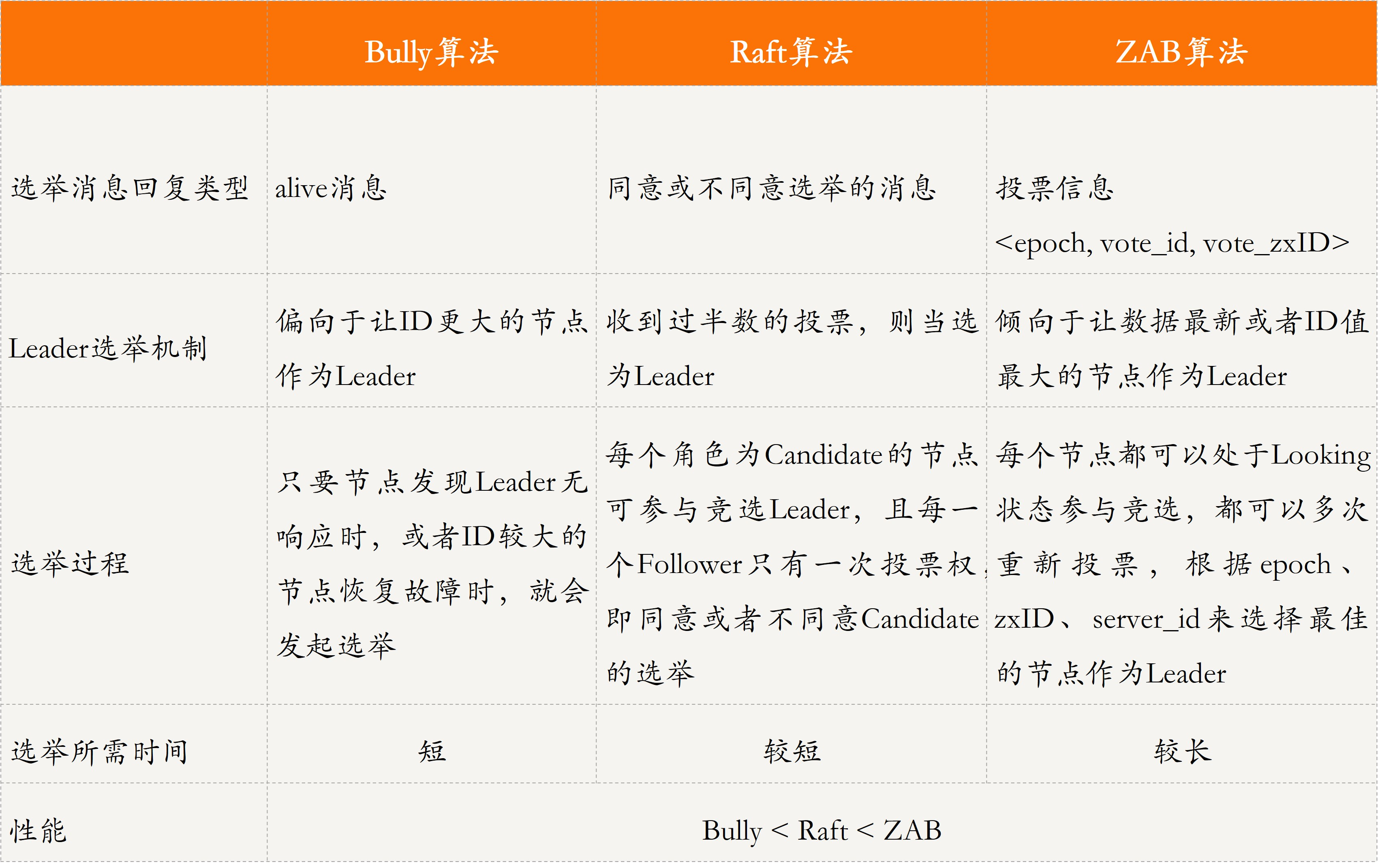
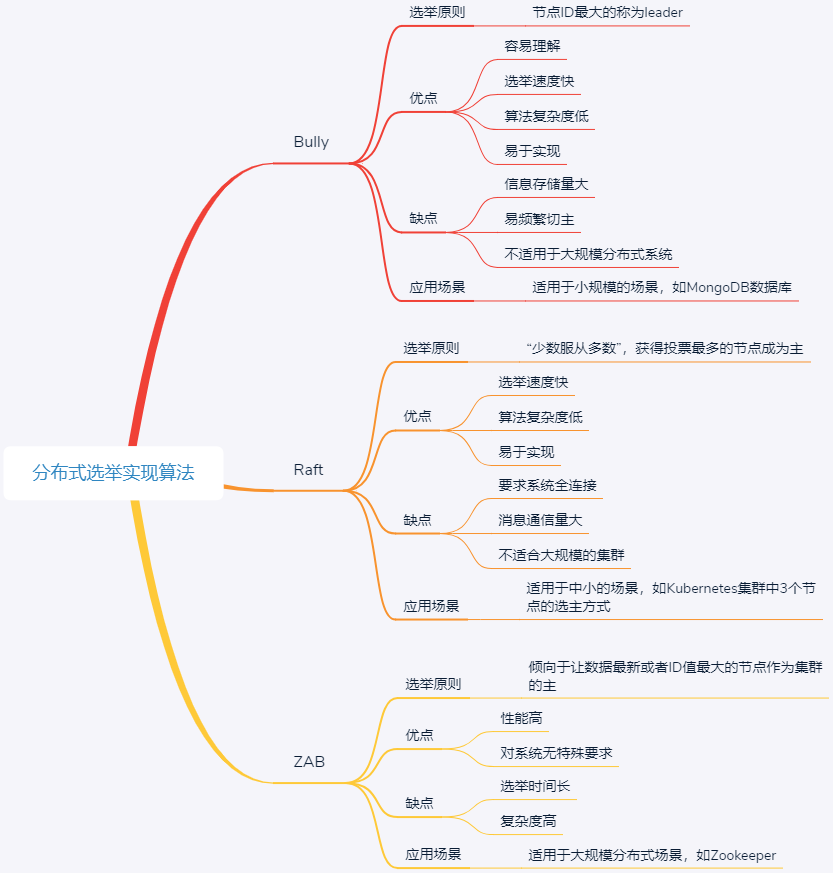
Bully算法是最常见的选举算法,要求每个节点对应一个序号,序号最高的节点为leader。leader宕机后次高序号的节点被重选为leader
Bully 算法在选举过程中,需要用到以下 3 种消息:
- Election 消息,用于发起选举;
- Alive 消息,对 Election 消息的应答;
- Victory 消息,竞选成功的主节点向其他节点发送的宣誓主权的消息
选举流程
- 集群中每个节点判断自己的 ID 是否为当前活着的节点中 ID 最大的,如果是,则直接向其他节点发送 Victory 消息,宣誓自己的主权;
- 如果自己不是当前活着的节点中 ID 最大的,则向比自己 ID 大的所有节点发送 Election 消息,并等待其他节点的回复;
- 若在给定的时间范围内,本节点没有收到其他节点回复的 Alive 消息,则认为自己成为主节点,并向其他节点发送 Victory 消息,宣誓自己成为主节点;
- 若接收到来自比自己 ID 大的节点的 Alive 消息,则等待其他节点发送 Victory 消息;若本节点收到比自己 ID 小的节点发送的 Election 消息,则回复一个 Alive 消息,告知其他节点,我比你大,重新选举
优缺点以及应用场景
优点:
Bully 算法的选择特别霸道和简单,谁活着且谁的 ID 最大谁就是主节点,其他节点必须无条件服从。这种算法的优点是,选举速度快、算法复杂度低、简单易实现
缺点:
- 需要每个节点有全局的节点信息,因此额外信息存储较多;
- 其次,任意一个比当前主节点 ID 大的新节点或节点故障后恢复加入集群的时候,都可能会触发重新选举,成为新的主节点,如果该节点频繁退出、加入集群,就会导致频繁切主
应用场景:
MongoDB 的副本集故障转移功能
MongoDB 的分布式选举中,采用节点的最后操作时间戳来表示 ID,时间戳最新的节点其 ID 最大,也就是说时间戳最新的、活着的节点是主节点
Raft算法(多数派)
Raft 算法是典型的多数派投票选举算法,核心思想是“少数服从多数”,获得投票最多的节点成为主
采用 Raft 算法选举,集群节点的角色有 3 种:
Leader,即主节点,同一时刻只有一个 Leader,负责协调和管理其他节点;Candidate,即候选者,每一个节点都可以成为 Candidate,节点在该角色下才可以被选为新的 Leader;Follower,Leader 的跟随者,不可以发起选举
选举流程
- 初始化时,所有节点均为 Follower 状态。
- 开始选主时,所有节点的状态由 Follower 转化为 Candidate,并向其他节点发送选举请求。
- 其他节点根据接收到的选举请求的先后顺序,回复是否同意成为主。这里需要注意的是,在每一轮选举中,一个节点只能投出一张票。
- 若发起选举请求的节点获得超过一半的投票,则成为主节点,其状态转化为 Leader,其他节点的状态则由 Candidate 降为 Follower。Leader 节点与 Follower 节点之间会定期发送心跳包,以检测主节点是否活着。
- 当 Leader 节点的任期到了,即发现其他服务器开始下一轮选主周期时,Leader 节点的状态由 Leader 降级为 Follower,进入新一轮选主
优缺点以及应用场景
优点:
- 选举速度快、算法复杂度低、易于实现
- 稳定性比 Bully 算法好,这是因为当有新节点加入或节点故障恢复后,会触发选主,但不一定会真正切主,除非新节点或故障后恢复的节点获得投票数过半,才会导致切主
缺点:
要求系统内每个节点都可以相互通信,且需要获得过半的投票数才能选主成功,因此通信量大
应用场景:
Google 开源的 Kubernetes, 采用了 etcd 组件就是采用了 Raft 算法来实现选主和一致性的
ZAB算法(多数派)
ZAB 选举算法的核心是“少数服从多数,ID 大的节点优先成为主”,因此选举过程中通过 (vote_id, vote_zxID) 来表明投票给哪个节点,其中 vote_id 表示被投票节点的 ID,vote_zxID 表示被投票节点的服务器 zxID。ZAB 算法选主的原则是:server_zxID 最大者成为 Leader;若 server_zxID 相同,则 server_id 最大者成为 Leader
使用 ZAB 算法选举时,集群中每个节点拥有 3 种角色:
Leader,主节点;Follower,跟随者节点;Observer,观察者,无投票权。
对应到选举过程中,集群中的节点拥有 4 个状态:
Looking 状态,即选举状态。当节点处于该状态时,它会认为当前集群中没有 Leader,因此自己进入选举状态Leading 状态,即领导者状态,表示已经选出主,且当前节点为 LeaderFollowing 状态,即跟随者状态,集群中已经选出主后,其他非主节点状态更新为 Following,表示对 Leader 的追随。Observing 状态,即观察者状态,表示当前节点为 Observer,持观望态度,没有投票权和选举权
选举流程
- 当系统刚启动时,3 个服务器当前投票均为第一轮投票,即 epoch=1,且 zxID 均为 0。此时每个服务器都推选自己,并将选票信息 广播出去
- 根据判断规则,由于 3 个 Server 的 epoch、zxID 都相同,因此比较 server_id,较大者即为推选对象,因此 Server 1 和 Server 2 将 vote_id 改为 3,更新自己的投票箱并重新广播自己的投票
- 此时系统内所有服务器都推选了 Server 3,因此 Server 3 当选 Leader,处于 Leading 状态,向其他服务器发送心跳包并维护连接;Server1 和 Server2 处于 Following 状态
优缺点以及应用场景
优点
- 算法性能高,对系统无特殊要求
- 算法选举稳定性比较好,当有新节点加入或节点故障恢复后,会触发选主,但不一定会真正切主
缺点
- 采用广播方式发送信息,若节点中有 n 个节点,每个节点同时广播,则集群中信息量为 n*(n-1) 个消息,容易出现
广播风暴(类似分布式互斥中的分布式算法的“信令风暴”) - 除了投票,还增加了对比节点 ID 和数据 ID,这就意味着还需要知道所有节点的 ID 和数据 ID,所以选举时间相对较长
应用场景
为 ZooKeeper 实现分布式协调功能而设计的
总结分析
三种算法对比分析
思维导图总结
思考拓展
1. 为什么“多数派”选主算法通常采用奇数节点,而不是偶数节点呢
可能会出现两个节点均获得一半投票的情况,采用偶数节点时无法选出主,必须重新投票选举。但即使重新投票选举,两个节点拥有相同投票数的概率也会很大
2. 分布式选举和一致性的关系是什么
一致性是指多个副本之间,在同一时刻能否有同样的值。分布式选举通常是实现一致性的基础,通过选举出主节点协调和管理其他节点,从而保证其他节点的有序运行以及各个节点之间的一致性
3. 是否存在一个集群中有双主的场景?
双主的情况,一般是因为网络故障,比如网络分区(某一时刻集群因为网络不通形成两个网络集群)等导致的。出现双主的期间,如果双主均提供服务,可能会导致集群中数据不一致。所以,需要根据业务对数据不一致的容忍度来决定是否允许双主情况下提供服务
联想记忆: 集群的脑裂现象,参考: