场景
需要对数据进行加工处理, 返回计算指标数据给前端绘制成折线图展示
目标字段和对比字段类型都没有限制,所以存在几种情况
当对比字段是连续型时:
横轴是目标字段,纵轴为“对比字段的均值、最大值、最小值、中位数”,共4条折线, 如下图: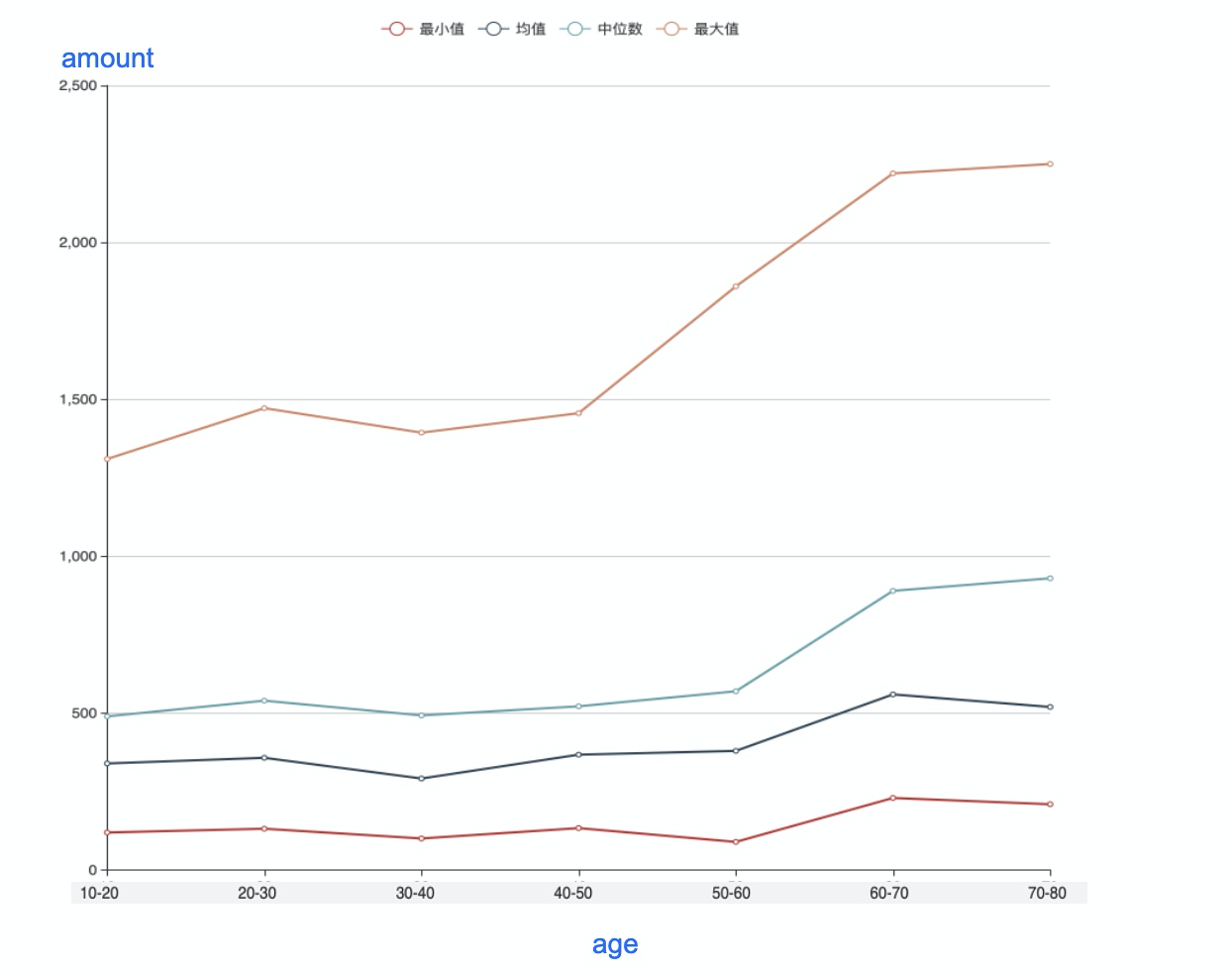
当对比字段是离散型时:
横轴是目标字段,纵轴为对比字段对于不同目标字段的Count统计值, 对不同的对比字段生成不同的折线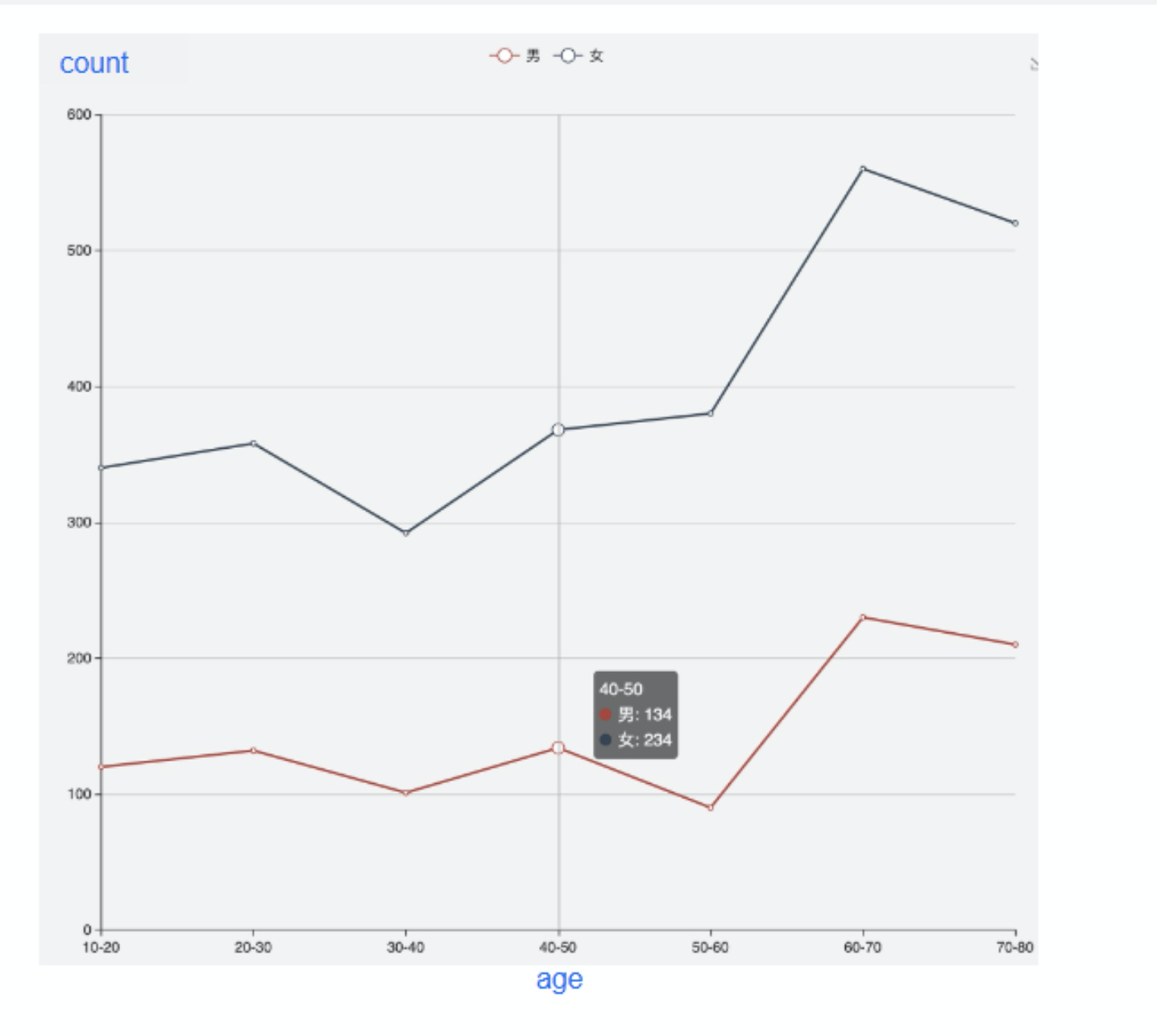
最初的想法
- 针对第1种情况: 先按目标字段的值分组进行统计, 然后统计对比字段在不同组别中的最大最小值等统计信息, 实现方法就是先
groupby, 然后利用max(),min()等算子统计 - 对于第2种情况: 也是先按目标字段的值分组进行统计, 但是接着还需要对对比字段的值进行分组统计不同值的Count计数, 这涉及到 多次
groupby分组操作
难点
- 当目标字段有很多时, 第一种情况就需要循环遍历计算过程了, 不太合理
- 目标字段和对比字段都很多时, 针对第二种情况, 假如各有 1000 个, 两次
groupby操作就是 1000 * 1000 = 100万的量级了, 性能太差, 实际中也发现很容易就发生内存溢出. - 两种情况的难点都在于随着字段一多然后因为涉及到多维度的指标统计计算成本呈指数级增长
优化思路
偶然联想到Mysql的查询优化, 有场景类似, 也是多条件联合查询时, 然后通过建联合索引进行优化, 于是我尝试借鉴这种思想来实现优化我的计算过程
具体实现
我这里主要编程语言为
Python, 示例代码针对于上面难点2的情况, 不过思想都是一样的.Pyspark支持自定义函数,然后通过lambda表达式应用处理数据, 就是一个 UDF(用户自定义函数)的概念优化概括
1
2
3
4
5groupBy(k1).groupBy(v1).groupBy(k2).count()
==> rdd.map(Row(k1=v1, k2=v2), func)
==> Row(k1&&KEY&&v1&&KEY&&k2, 1)
==> reduceBykey(k1&&KEY&&v1&&KEY&&k2)
==> (k1&&KEY&&v1&&KEY&&k2, count)自定义函数拼接key
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def generate_grouped_data_discrete(row):
"""
分别以目标字段和对比字段作为key分组统计的话性能太差,所以将目标字段和对比字段的值合并作为一个key然后进行计算
:param row:
:return:
"""
field_key_list = list()
# 核心思想实现, 将目标字段名, 目标字段值以及对比字段值合并成一个key
for field in self.aims_fields:
key = field["name"] + '&&KEY&&' + \
str(row[field["name"]]) + '&&KEY&&' + \
str(row[self.compared_fields[0]["name"]])
field_key_list.append(key)
return field_key_list然后利用RDD计算统计Count值
1
2
3
4reduce_result = df.rdd.flatMap(
lambda row: generate_grouped_data_discrete(row)).map(
lambda word: [word, 1]).reduceByKey(
lambda a, b: a + b)最后将数据切割处理成我们需要的数据格式
1
2result_rdd = reduce_result.map(
lambda group_data: generate_map_collect(group_data))切割数据处理的自定义函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def generate_map_collect(group_data):
"""
拆分结果
:param group_data: 字典数据
:return:
"""
all_data = str(group_data[0]).split('&&KEY&&')
# 目标字段名
aim_field_name = all_data[0]
# 目标字段对应值
aim_field_value = all_data[1]
# 对比字段对应值
compared_field_value = all_data[2]
# 组内总和, 即每个目标字段区间上对比字段的count计数
section_sum = group_data[1]
return (aim_field_name, {aim_field_value:
{compared_field_value: section_sum}})核心思想实现就在于两个自定义处理函数, 主要是第一个函数中的拼接操作,
RDD最开始的数据类似这样:Row(k1=v1, k2=v2), 拼接后会变成Row(k1&&KEY&&v1&&KEY&&k2), 就相当于将本来需要多次groupby分组的key合并成了一个
举一反三
总结的时候发现还有很多类似的场景:
大数据场景中的二次排序
参考链接: 二次排序的应用
redis的组合优化思想
参考链接: 每秒30W次的点赞业务,怎么优化?