Spark调度系统
一、主要工作流程
两个核心:DAGScheduler和TaskScheduler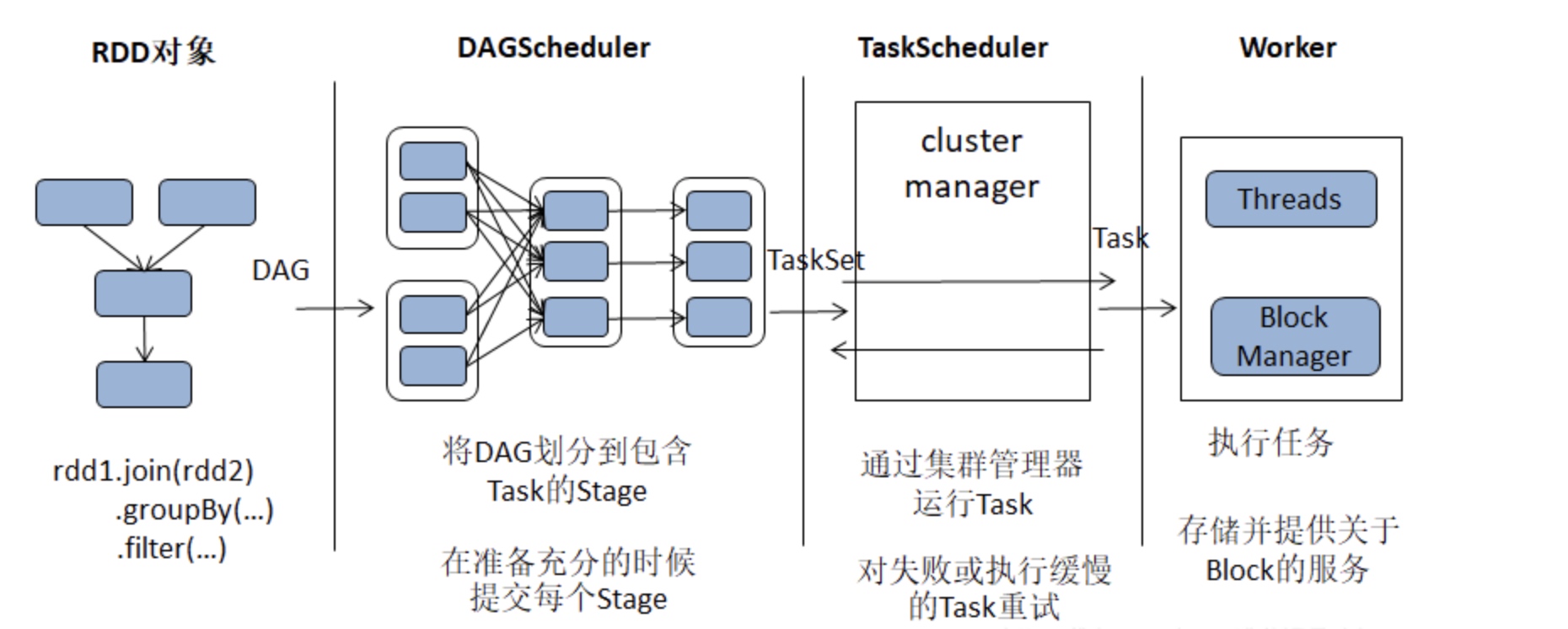
build operator DAG
用户提交的Job将首先被转换为一系列RDD并通过RDD之间的依赖关系(Dependency)构建DAG, 然后将RDD构成的DAG提交到调度系统
split graph into stage of tasks
DAGScheduler负责接收由RDD构成的DAG,将一系列RDD划分到不同的Stage。根据 Stage的不同类型(ResultStage和 ShuffleMapStage), 给 Stage 中未完成的 Partition 创建不同类型的Task(ResultTask和 ShuffleMapTask)。 每个Stage将因为未完成Partition的多少, 创建零到多个Task。DAGScheduler最后将每个Stage中的Task以任务集合(TaskSet)的形式提交给TaskSchduler继续处理
launch tasks via cluster manager
使用集群管理器(cluster manager)分配资源与任务调度, 对于失败的任务还会有一定的重试与容错机制。TaskScheduler负责从DAGScheduler接收TaskSet, 创建TaskSetManager对TaskSet进行管理,并将此TaskSetManager添加到调度池中, 最后将对Task的调度交给后端接口(SchedulerBackend)处理。SchedulerBackend首先申请TaskSheduler,按照Task调度算法(FIFO和FAIR),对调度池中所有TaskSetManager进行排序,然后对TaskSet按照最大本地性原则分配资源,最后在各个分配的节点上运行TaskSet中的Task
execute tasks
执行任务,并将任务中间结果和最终结果存入存储体系
二、RDD 详解
RDD简单总结
参考RDD总结
分区计算器Partitioner
当存在shuffle依赖关系时, 利用Partitioner来确定上下游RDD之间的分区依赖关系
1 | abstract class Partitioner extends Serializable { |
三、Stage
官方解释:
1 | /** |
Stage是一系列并行计算且具有相同依赖的task的集合,在执行流程中DAGScheduler会将一系列RDD划分到不同的Stage并构建它们之间的依赖关系,使不存在依赖关系的Stage并行执行,保证依赖关系的Stage顺序执行。Stage分为需要处理Shuffle的ShuffleMapStage和最下游的ResultStage,ResultStage是最后执行的Stage,比如执行count()等action算子的任务
Job中所有Stage的提交过程包括反向驱动与正向提交
反向驱动
所谓反向驱动,就是从最下游的ResultStage开始,由ResultStage驱动所有父Stage的执行,这个驱动过程不断向祖先方向传递,直到最上游的Stage为止
正向提交
正向提交,就是前代Stage先于后代Stage将Task提交给TaskScheduler, “代代相传”,直到ResultStage最后一个将Task提交给TaskScheduler
四、DAGScheduler
介绍
DAGScheduler通过计算将DAG中一系列RDD划分到不同的Stage,然后构建这些Stage之间的关系,最后将每个Stage按照Partition切分为多个Task,并以Task集合(即TaskSet)的形式提交给底层的TaskScheduler
DAGScheduler依赖的一些组件: DAGSchedulerEventProcessLoop, JobListener及ActiveJob
JobListener与JobWaiter
JobListener用于监听作业中每个Task执行成功或失败,JobWaiter继承实现了JobListener, 用于等待整个Job执行完毕,然后调用给定的处理函数对返回结果进行处理并最终确定作业的成功或失败
源码实现的一些思考:
- 通过Scala的异步编程
Future/Promise实现了任务状态的检测监听, 这块还不太理解,等后面系统学习一下Scala再回顾一下 - JobWaiter中的定义了一个
cancel()方法取消Job执行实际上调用了 DAGScheduler 的cancelJob()方法 - JobWaiter 中继承 JobListener 实现的taskSucceeded()方法中为了保证线程安全用到了
synchronized给对象加锁, 联想到RDD中的stateLock,也用到了synchronized加锁
ActiveJob
ActiveJob表示已经激活的Job, 即DAGScheduler接收处理的Job
DAGSchedulerEventProcessLoop
DAGSchedulerEventProcessLoop是DAGScheduler内部的事件循环处理器, 实现原理类似于LiveListenerBus
DAGScheduler与Job的提交
简要流程概括, 这里以执行count算子为例:
首先执行count算子会创建调用SparkContext的runJob()方法
1
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
然后接着传递调用DAGScheduler的runJob()方法
1
2
3
4
5def runJob[T, U: ClassTag](...): Unit = {
....
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
....
}DAGScheduler通过执行submitJob()方法提交Job
1
2
3
4
5
6
7
8
9
10
11
12
13def runJob[T, U](...): Unit = {
val start = System.nanoTime
// 执行submitJob()方法
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format(...))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format(...))
...
}
}submitJob()生成一个JobWaiter的实例监听Job的执行情况, 向DAGSchedulerEventProcessLoop发送JobSubmitted事件
1
2val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(....))当eventProcessLoop对象投递了JobSubmitted事件之后,对象内的
eventThread线程实例对事件进行处理,不断从事件队列中取出事件,调用onReceive函数处理事件,当匹配到JobSubmitted事件后,调用DAGScheduler的handleJobSubmitted函数并传入jobid、rdd等参数来处理JobhandleJobSubmitted执行过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22private[scheduler] def handleJobSubmitted(...) {
var finalStage: ResultStage = null
try {
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
....
}
.....
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
.....
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}由源码分析可以概括执行过程如下
首先调用createResultStage方法创建ResultStage, 这里就开始了Stage的构建过程, 详见下节Stage的构建过程
创建ActiveJob
将JobId与刚创建的ActiveJob的对应关系放入jobIdToActiveJob中
将刚创建的ActiveJob放入activeJobs集合中
使ResultStage的_activeJob属性持有刚创建的ActiveJob
获取当前Job的所有Stage对应的StageInfo(即数组stageInfos)
向listenerBus(LiveListenerBus)投递SparkListenerJobStart事件,进而引发所有关注此事件的监听器执行相应的操作
调用submitStage方法提交Stage,所有parent Stage都计算完成,才能提交
submitStage三种调用逻辑:
submitMissingTasks(stage,jobId.get):如果所有parent stage已经完成,则提交stage所包含的tasksubmitStage(parent):有parent stage未完成,则递归提交abortStage:无效stage,直接停止
DAGScheduler完成任务提交后,在判断哪些Partition需要计算,就会为Partition生成Task,然后封装成TaskSet,提交至TaskScheduler。等待TaskScheduler最终向集群提交这些Task,监听这些Task的状态
构建Stage
前面我们看到handleJobSubmitted执行过程中调用createResultStage方法创建ResultStage
1 | private def createResultStage(....): ResultStage = { |
根据源码分析,详细的处理步骤如下:
调用
getOrCreateParentStages方法获取所有父Stage的列表,父Stage主要是宽依赖对应的StagegetOrCreateParentStages处理步骤:
1
2
3
4
5private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}- 调用DAGScheduler的
getShuffleDependencies方法获取当前给到的RDD的所有ShuffleDependency的序列, 逐个访问其依赖的非Shuffle的RDD,获取所有非Shuffle的RDD的ShuffleDependency依赖 - 调用DAGScheduler的
getOrCreateShuffleMapStage方法为每一个ShuffleDependency获取或者创建对应的ShuffleMapStage, 并返回得到的ShuffleMapStage列表
- 调用DAGScheduler的
getOrCreateShuffleMapStage方法处理步骤:
啊
生成Stage的身份标识id, 并创建ResultStage
将ResultStage注册到stageIdToStage中
调用updateJobIdStageIdMaps方法更新Job的身份标识与ResultStage及其所有祖先的映射关系