Livy系列-Livy Session详解
内容整理自:
- 简书作者-牛肉圆粉不加葱 Apache Livy文集
概要
Livy 共有两种 job,分别是 session 和 batch。session 和 batch 的创建过程也很不相同,batch 的创建以对应的 spark app 启动为终点;而 session 除了要启动相应的 spark app,还要能支持共享 sparkContext 来接受一个个 statements 的提交及运行,我将 session 的创建分为两个大步骤:
client 端:运行在 LivyServer 中,接受 request 直到启动 spark app(注意,这里虽然叫 client 端,但是运行在 LivyServer 中的)server 端(driver 内部):session 对应的 spark app driver 的启动
client端
整体流程
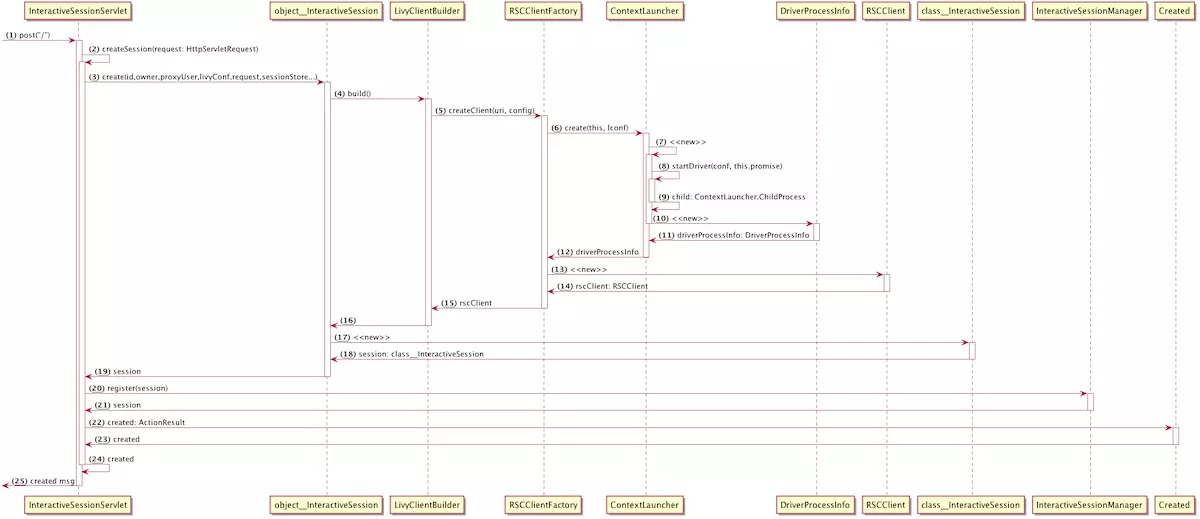
- 启动 session 对应的 spark app
- 与 driver 建立连接
- Session 的创建与初始化
启动 session 对应的 spark app
核心方法为: ContextLauncher#startDriver, 可以分为两个大步骤:
- 启动 spark app
- 等待 SparkSubmit 退出
启动 spark app
session 对应的 spark app 的 mainClass 为 RSCDriverBootstrapper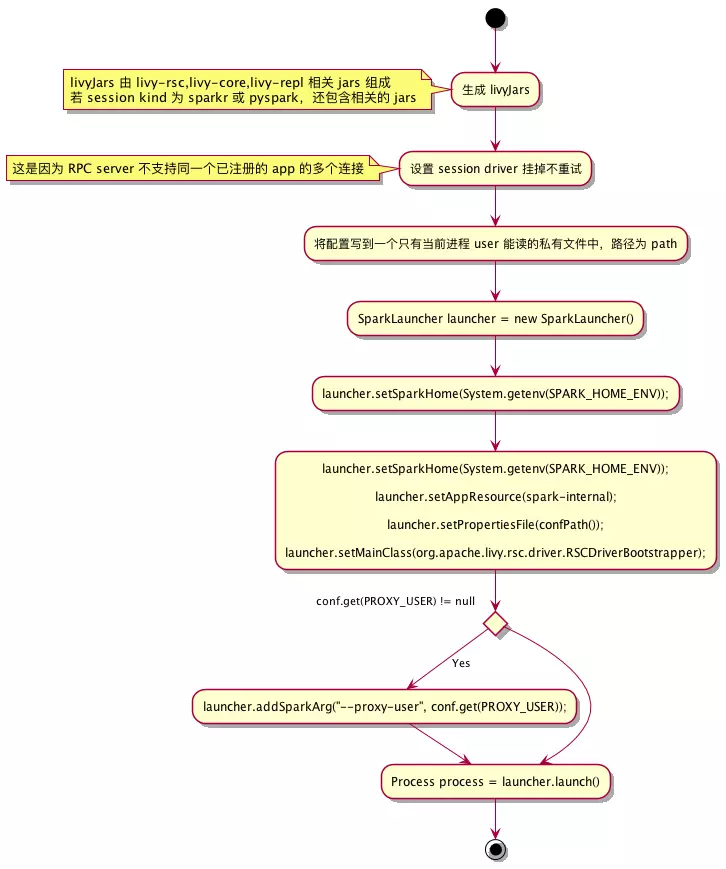
调用startDriver()方法, new 一个 SparkLauncher 对象,进行了配置、资源、mainClass 等设置,然后调用 launch() 方法拿到了 SparkSubmit 进程的 对应的 Process 对象 process.
等待 SparkSubmit 退出
SparkLauncher#launch() 返回的进程是 SparkSubmit 进程,再返回 process 后,会 new 一个 ContextLauncher.ChildProcess 对象,在过程中会新启动一个线程来一直等待 SparkSubmit 进程退出,该线程中的逻辑如下:
1 | public void run() { |
与 driver 建立连接
session 最大的特点就是可以共享 SparkContext,让用户提交的多个代码片段都能跑在一个 SparkContext 上(联想记忆到 IO多路复用,http长连接),这有两个好处:
- 大大加速任务的启动速度, yarn上启动一个app比较耗时,而使用 session,除了启动 session 也需要相当的耗时外,之后提交的代码片段都将立即执行(联想到
http长连接) - 共享 RDD、table:持久化的 RDD、table 都可以被之后的代码片段使用,这在不同用户需要在相同的 RDD、table 上做计算的场景非常有用(联想到IO多路复用, 网络复用)
由于 driver 可能被 yarn 调度到任何一个节点启动,所以无法由 LivyServer 主动与 driver 建立连接,而是预先在 client 端建立好 RpcServer 等待 driver 来连接。所以是先在client端创建一个RpcServer, 等待driver端连接,连接成功后client获取到了driver端的
信息再去连接到driver端的 RpcServer。总结起来就是三步:
client 传递其 RpcServer 信息给 driver
时序图中的第 (5) 步:RSCClientFactory#createClient,在该调用中创建了一个org.apache.livy.rsc.rpc.RpcServer对象赋值给成员 server。driver 连接 client 并传递其 RpcServer 信息(在
RSCDriver#initializeServer中实现)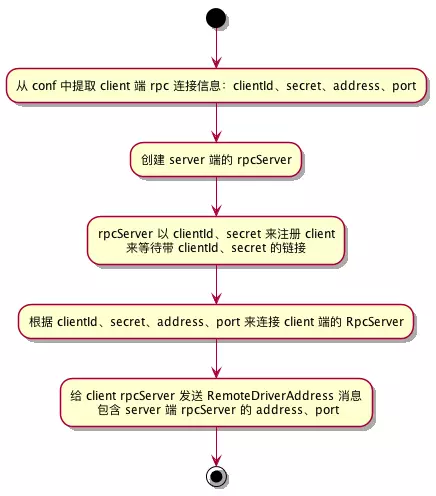
client 接收 driver rpcServer 地址信息并连接
Session 的创建与初始化
在与 driver 建立连接之后,会使用 rscClient、livyConf 等信息来创建 InteractiveSession 对象并进行初始化,流程如下: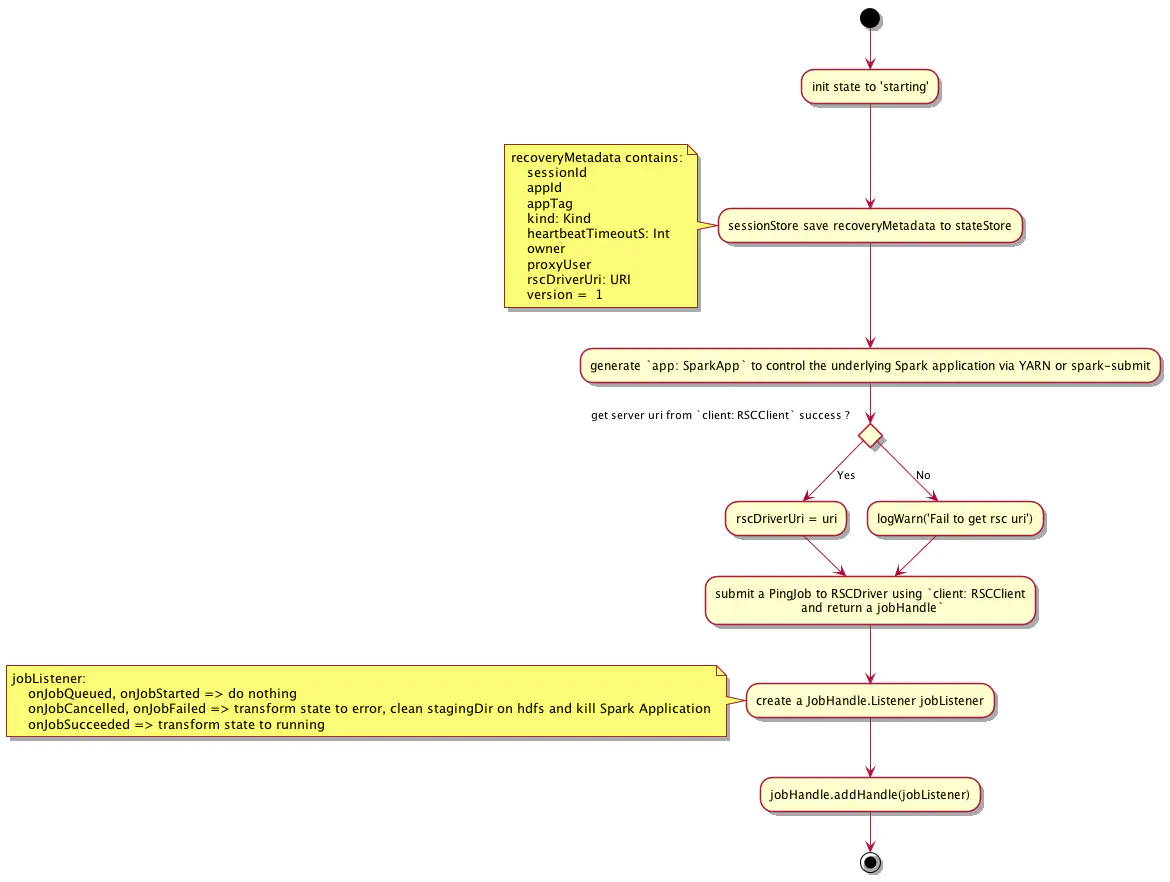
关键的步骤:
- 将 session 信息存储到 state store 中以便livy server 挂掉后能进行 recovery 恢复
- 向 driver 发送一个空的 PingJob 来确定 driver 的状态是否 ok,若 PingJob 成功执行,则说明 driver 状态 ok,将 session 置为 running 状态;若出错或失败,则说明 driver 出了一些问题,则将 session 的状态置为 error
成功完成 session 的创建及初始化后,会将 session 添加到 SessionManager 中进行统一管理,SessionManager 的主要职责包括:
- 持有所有 sessions
- 清理过期 session
- 从 state store 中恢复 sessions
server 端(driver 内部)
概要
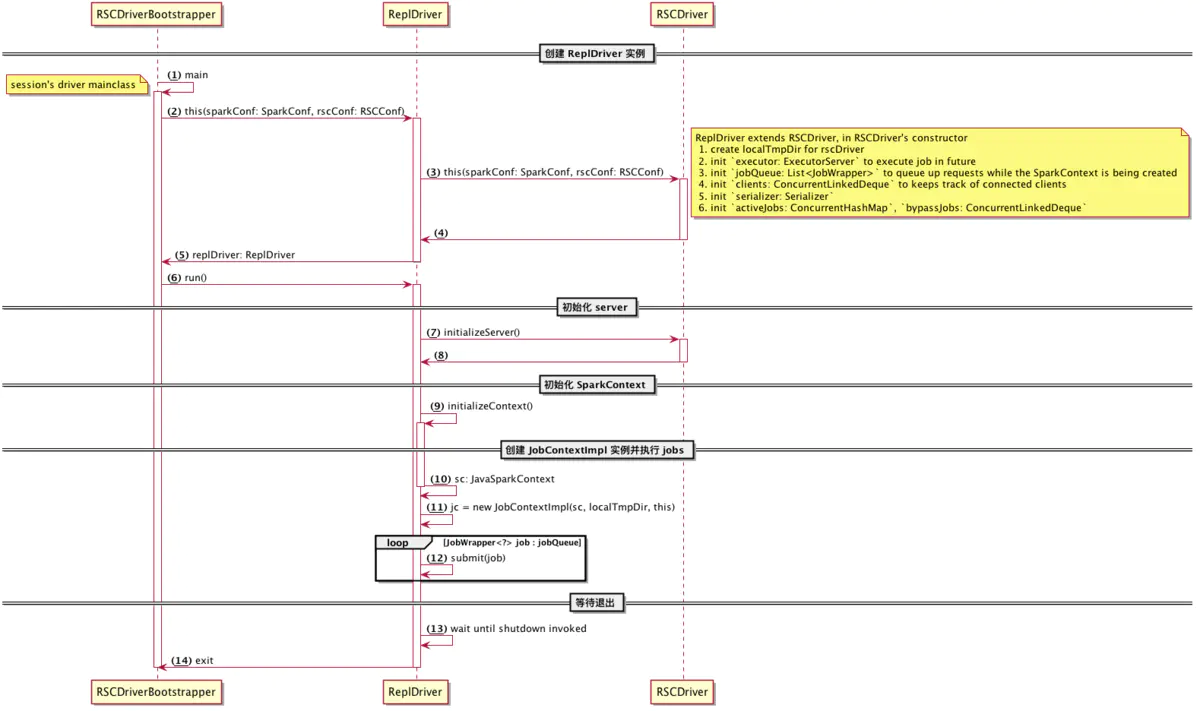
如图所示, driver 内部的启动流程可以分为以下五个步骤:
- 创建 ReplDriver 实例
- 初始化 server
- 初始化 SparkContext
- 创建 JobContextImpl 实例并执行 jobs
- 等待退出
创建 ReplDriver 实例
ReplDriver 是 InteractiveSession 对应的 Spark App driver,用来接收 livy server 的各种请求并进行处理。也是 RSCDriver 的子类,RSCDriver:
- 持有等待 RSCClient 进行连接的 RpcServer server
- 初始化 SparkContext
- 处理各种请求:CancelJob、EndSession、JobRequest、BypassJobRequest、SyncJobRequest、GetBypassJobStatus
- 处理 add file 请求
初始化 server
这一步在 RSCDriver#initializeServer() 中调用,用于连接 client 并告知 server 端 rpc 地址,client 获知 server rpc 地址后会进行连接并发送请求
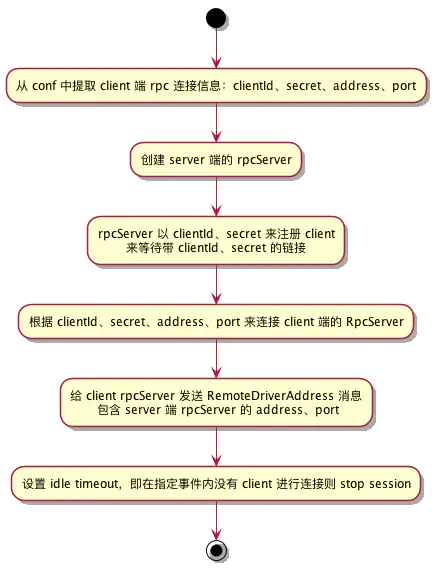
初始化 SparkContext
分为3步:
根据不同的 kind 创建不同类型的代码解释器
创建 repl/Session, 其主要职责是:
- 启动 interpreter,并获取 SparkContext
- 持有线程池来异步执行 statements(通过 interpreter 来执行)
- 持有线程池来异步取消 statements
- 管理一个 session 下所有的 statements
调用
interpreter#start方法启动 Session
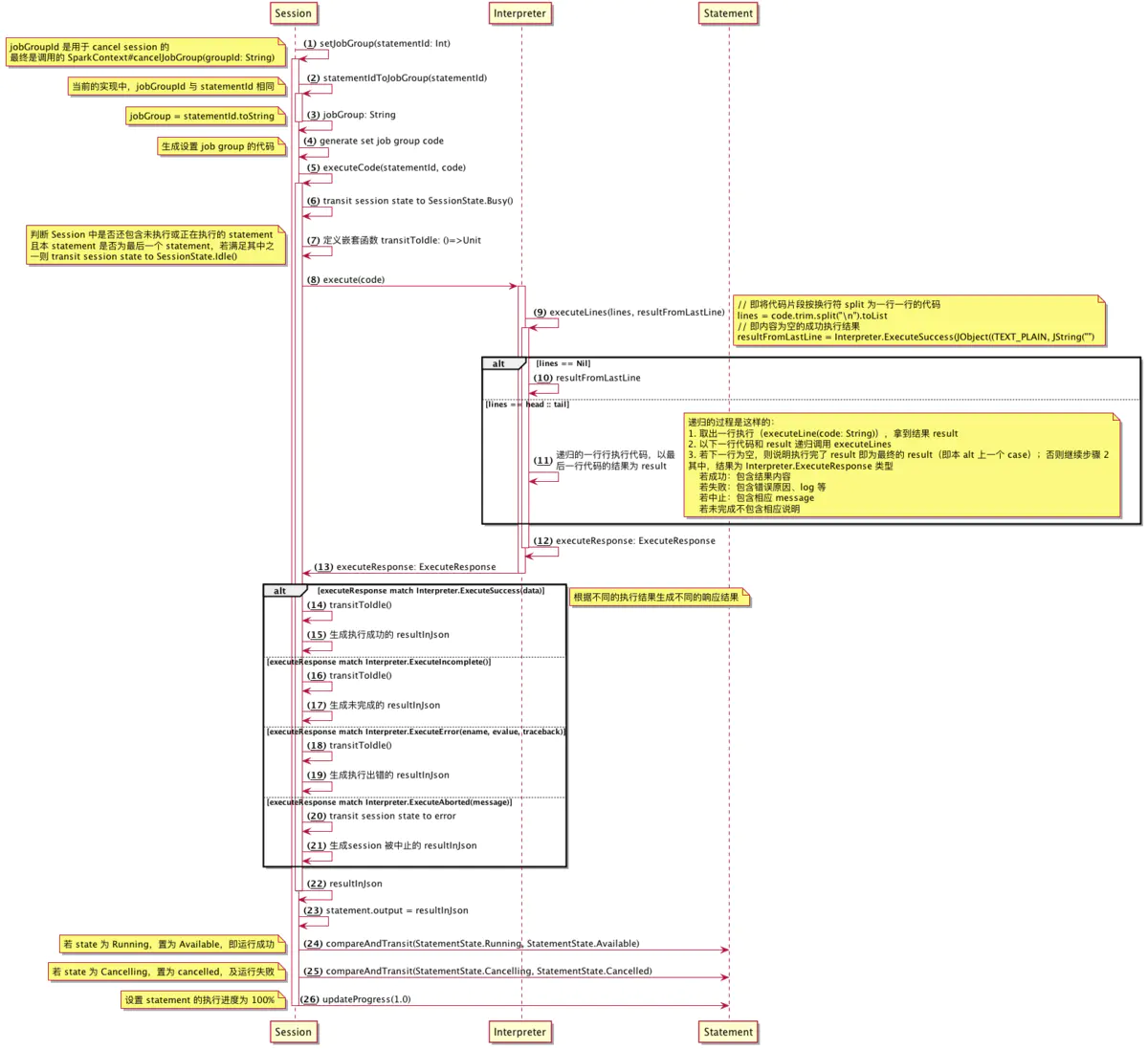
如何执行代码片段
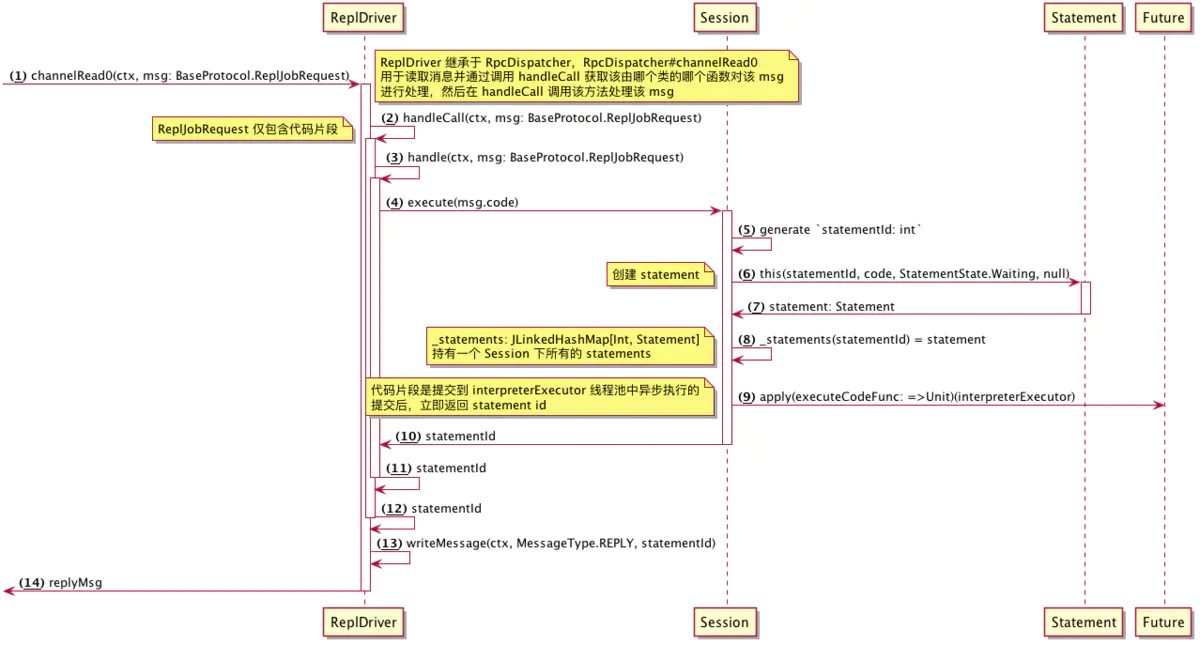
executeCodeFunc()方法分析
即上图中的第 9 步中的 executeCodeFunc,用来真正运行代码片段的函数,流程如下