Livy系列-基于Spark的REST服务Livy简介
内容整理自:
Livy简介
Apache Livy是一个基于Spark的开源REST服务,它能够以REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行, 它提供了以下这些基本功能:
- 提交Scala, Python或是R代码片段到远端的Spark集群上执行。
- 提交Java, Scala, Python所编写的Spark作业到远端的Spark集群上执行。
- 提交批处理应用到集群中运行
关于Livy REST API的使用,参考官方文档
Livy基本架构
Livy是一个典型的REST服务架构,它一方面接受并解析用户的REST请求,转换成相应的操作;另一方面它管理着用户所启动的所有的Spark集群
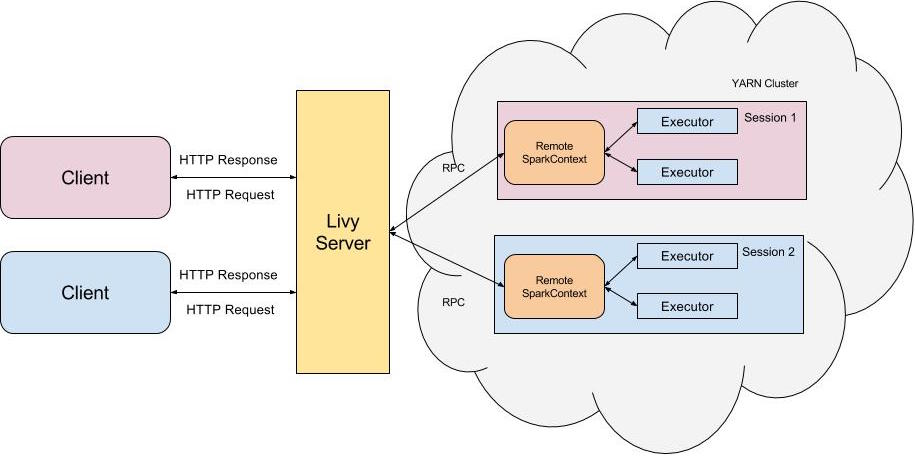
用户可以以REST请求的方式通过Livy启动一个新的Spark集群,Livy将每一个启动的Spark集群称之为一个会话(session),一个会话是由一个完整的Spark集群所构成的,并且通过RPC协议在Spark集群和Livy服务端之间进行通信。根据处理交互方式的不同,Livy将会话分成了两种类型:
交互式会话(interactive session)。这与Spark中的交互式处理相同,交互式会话在其启动后可以接收用户所提交的代码片段,在远端的Spark集群上编译并执行。批处理会话(batch session)。用户可以通过Livy以批处理的方式启动Spark应用,这样的一个方式在Livy中称之为批处理会话,这与Spark中的批处理是相同的
Livy的企业级特性
多用户支持
假定用户tom向Livy服务端发起REST请求启动一个新的会话,而Livy服务端则是由用户livy启动的,这个时候所创建出来Spark集群的用户是谁呢,会是用户tom还是livy?在默认情况下这个Spark集群的用户是livy。这会带来访问权限的问题:用户tom无法访问其拥有权限的资源,而相对的是他却可以访问用户livy所拥有的资源。
为了解决这个问题Livy引入了Hadoop中的代理用户(proxy user)模式,代理用户模式广泛使用于多用户的环境,如HiveServer2。在此模式中超级用户可以代理成普通用户去访问资源,并拥有普通用户相应的权限。开启了代理用户模式后,以用户tom所创建的会话所启动的Spark集群用户就会是tom
端到端安全
- 基于Kerberos的Spnego认证实现客户端认证安全
- 使用标准的SSL来加密Http协议,保证客户端与Livy服务端之间Http传输的安全性
- 基于SASL认证的RPC通信机制保证Livy服务端和Spark集群之间网络通信安全
失败恢复机制
Livy提供了失败恢复的机制,当用户启动会话的同时Livy会在可靠的存储上记录会话相关的元信息,一旦Livy从失败中恢复过来时它会试图读取相关的元信息并与Spark集群重新连接。
为了使用该特性我们需要进行以下Livy配置:
1 | // 开启失败恢复功能 |
Livy与spark-jobserver对比
Livy的优势:
- Livy不需要对代码进行任何更改,而SJS作业必须扩展特定的类。
- Livy允许提交代码片段(包括Python)以及预编译的jar,而SJS只接受jar。
- 除了REST之外,Livy还有Java和Scala API。Python API正在开发中,SJS有一个“python绑定”
SJS优势:
- SJS可以管理jars,它允许您上传和存储Jars,部署作业的时候只需要通过单独的REST去调用。而Livy每次重新部署作业,都需要重新上传这些jar。
- 可以使用HOCON格式配置SJS作业,该格式可以作为REST调用提交
官方链接
Livy: https://livy.incubator.apache.org/
spark-jobserver: https://github.com/spark-jobserver/spark-jobserver