Hive概览
Hive基本架构
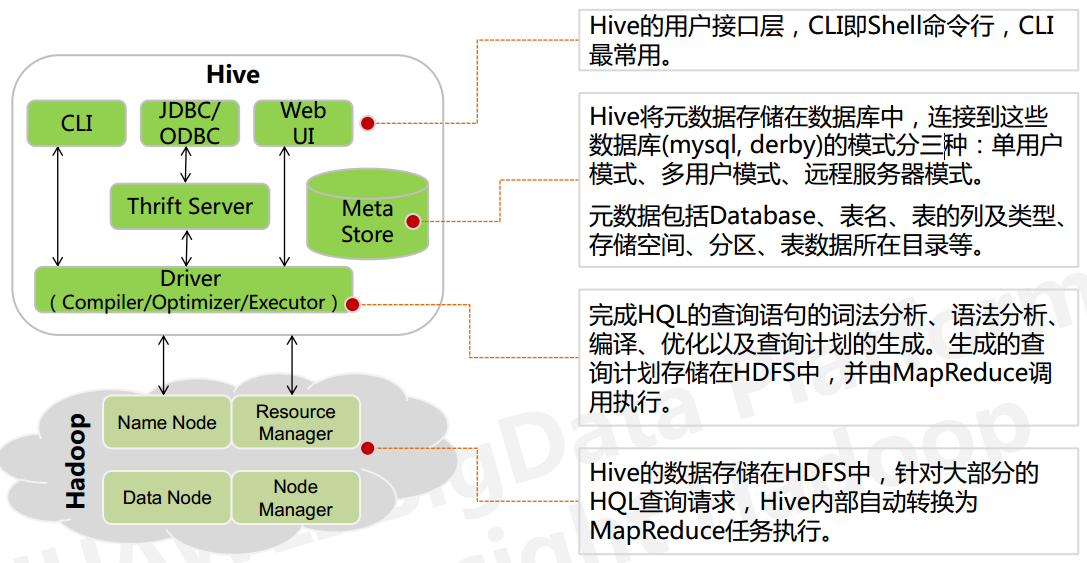
用户接口: CLI、JDBC/ODBC、Web UI层Trift Server: 支持多种语言程序来操纵HiveDriver: Driver驱动器、Compiler编译器、Optimizer优化器、Executor执行器Hive 的核心是驱动引擎, 驱动引擎由四部分组成:
- 解释器: 将HiveSQL语句转换成抽象语法树(AST)
- 编译器: 将抽象语法树转换成逻辑执行计划
- 优化器: 对逻辑执行计划进行优化
- 执行器: 调用底层的执行框架执行逻辑计划
元数据存储系统: Hive 中的元数据通常包括表的名字,表的列和分区及其属性,表的属性(内部表和 外部表),表的数据所在目录.Metastore 默认存在自带的
Derby数据库中,缺点就是不适合多用户操作,并且数据存 储目录不固定。数据库跟着 Hive 走,极度不方便管理
解决方案:通常存我们自己创建的 MySQL 库(本地 或 远程),Hive 和 MySQL 之间通过 MetaStore 服务交互
Hive中的表
Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大
分区表和分桶表
分区
按照数据表的某列或某些列分为多个区,分区为 HDFS 上表目录的子目录,数据按照分区存储在子目录中。如果查询的 where 字句的中包含分区条件,则直接从该分区去查找,而不是扫描整个表目录,合理的分区设计可以极大提高查询速度和性能
创建分区表
在 Hive 中可以使用 PARTITIONED BY 子句创建分区表
1 | CREATE EXTERNAL TABLE emp_partition( |
加载数据到分区表
加载数据到分区表时候必须要指定数据所处的分区
1 | # 加载部门编号为20的数据到表中 |
分桶
并非所有的数据集都可以形成合理的分区,分区的数量也不是越多越好,过多的分区条件可能会导致很多分区上没有数据。分桶是相对分区进行更细粒度的划分,将整个数据内容按照某列属性值得hash值进行区分
创建分桶表
在 Hive 中,我们可以通过 CLUSTERED BY 指定分桶列,并通过 SORTED BY 指定桶中数据的排序参考列
1 | CREATE EXTERNAL TABLE emp_bucket( |
加载数据到分桶表
1 | --1. 设置强制分桶,Hive 2.x 不需要这一步 |
内部表和外部表
区别
- 创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
- 删除表时:在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据
- 建表的时候外部表额外加上一个
external关键字
使用选择
- 如果数据的所有处理都在Hive中进行,那么倾向于选择内部表
- 使用外部表的场景主要是共享数据源的情况,可以使用外部表访问存储在 HDFS 上的初始数据,然后通过 Hive 转换数据并存到内部表中
自定义UDF
参考链接: Hive UDF
UDF(User Defined Function),即用户自定义函数,主要包含:
UDF(user-defined function): 一进一出,给定一个参数,输出一个处理后的数据 UDAF(user-defined aggregate function): 多进一出,属于聚合函数,类似于count、sum等函数 UDTF(user-defined table function): 一进多出,属于一个参数,返回一个列表作为结果
优化
(1) 数据倾斜
原因
- key分布不均匀
- 业务数据本身的特性
- SQL语句造成数据倾斜
解决方法
hive设置
hive.map.aggr=true和hive.groupby.skewindata=true有数据倾斜的时候进行负载均衡,当设定
hive.groupby.skewindata=true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job在根据预处理的数据结果按照 Group By Key 分布到Reduce中(这个过程可以保证相同的 Group By Key 被分布到同一个Reduce中),最后完成最终的聚合操作。SQL语句调整:
选用join key 分布最均匀的表作为驱动表。做好列裁剪和filter操作,以达到两表join的时候,数据量相对变小的效果。大小表Join: 使用map join让小的维度表(1000条以下的记录条数)先进内存, 在Map端完成Reduce。大表Join大表:把空值的Key变成一个字符串加上一个随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终的结果。count distinct大量相同特殊值:count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在做后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union.
(2)通用设置
hive.optimize.cp=true:列裁剪hive.optimize.prunner:分区裁剪hive.limit.optimize.enable=true:优化LIMIT n语句hive.limit.row.max.size=1000000:hive.limit.optimize.limit.file=10:最大文件数
(3)本地模式(小任务)
开启本地模式 hive> set hive.exec.mode.local.auto=true
job的输入数据大小必须小于参数:
hive.exec.mode.local.auto.inputbytes.max(默认128MB)job的map数必须小于参数:
hive.exec.mode.local.auto.tasks.max(默认4)job的reduce数必须为0或者1
(4)并发执行
开启并行计算 hive> set hive.exec.parallel=true
相关参数 hive.exec.parallel.thread.number:一次sql计算中允许并执行的 job 数量
(5)Strict Mode(严格模式)
主要是防止一群sql查询将集群压力大大增加
开启严格模式: hive> set hive.mapred.mode = strict
一些限制:
- 对于分区表,必须添加where对于分区字段的 条件过滤
- orderby语句必须包含limit输出限制
- 限制执行笛卡尔积 查询
(6)推测执行
1 | mapred.map.tasks.speculative.execution=true |
(7)分组
两个聚集函数不能有不同的DISTINCT列,以下表达式是错误的:
1
INSERT OVERWRITE TABLE pv_gender_agg SELECT pv_users.gender, count(DISTINCT pv_users.userid), count(DISTINCT pv_users.ip) FROM pv_users GROUP BY pv_users.gender;
SELECT语句中只能有GROUP BY的列或者聚集函数
hive.multigroupby.singlemar=true:当多个GROUP BY语句有相同的分组列,则会优化为一个MR任务
(8)聚合
开启map聚合 hive> set hive.map.aggr=true
相关参数
hive.groupby.mapaggr.checkinterval: map端group by执行聚合时处理的多少行数据(默认:100000)hive.map.aggr.hash.min.reduction: 进行聚合的最小比例(预先对100000条数据做聚合,若聚合之后的数据量 /100000的值大于该配置0.5,则不会聚合)hive.map.aggr.hash.percentmemory:map端聚合使用的内存的最大值hive.map.aggr.hash.force.flush.memory.threshold: map端做聚合操作是hash表的最大可用内容,大于该值则会触发flushhive.groupby.skewindata:是否对GroupBy产生的数据倾斜做优化,默认为false
(9)合并小文件
hive.merg.mapfiles=true:合并map输出hive.merge.mapredfiles=false:合并reduce输出hive.merge.size.per.task=256*1000*1000:合并文件的大小hive.mergejob.maponly=true:如果支持CombineHiveInputFormat则生成只有Map的任务执行mergehive.merge.smallfiles.avgsize=16000000:文件的平均大小小于该值时,会启动一个MR任务执行merge。
(10)自定义map/reduce数目
Map数量相关的参数
mapred.max.split.size:一个split的最大值,即每个map处理文件的最大值mapred.min.split.size.per.node:一个节点上split的最小值mapred.min.split.size.per.rack:一个机架上split的最小值
Reduce数量相关的参数
mapred.reduce.tasks: 强制指定reduce任务的数量hive.exec.reducers.bytes.per.reducer每个reduce任务处理的数据量hive.exec.reducers.max每个任务最大的reduce数 [Map数量 >= Reduce数量 ]
(11)使用索引:
hive.optimize.index.filter:自动使用索引hive.optimize.index.groupby:使用聚合索引优化GROUP BY操作
支持的存储格式
ORC 和 Parquet 的综合性能突出,使用较为广泛,推荐使用
TextFile 存储为纯文本文件。 这是 Hive 默认的文件存储格式。这种存储方式数据不做压缩,磁盘开销大,数据解析开销大。SequenceFile: SequenceFile 是 Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用 Hadoop 的标准的 Writable 接口实现序列化和反序列化。它与 Hadoop API 中的 MapFile 是互相兼容的。Hive 中的 SequenceFile 继承自 Hadoop API 的 SequenceFile,不过它的 key 为空,使用 value 存放实际的值,这样是为了避免 MR 在运行 map 阶段进行额外的排序操作。RCFile: RCFile 文件格式是 FaceBook 开源的一种 Hive 的文件存储格式,首先将表分为几个行组,对每个行组内的数据按列存储,每一列的数据都是分开存储。ORC Files: ORC 是在一定程度上扩展了 RCFile,是对 RCFile 的优化。Avro Files: Avro 是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro 提供的机制使动态语言可以方便地处理 Avro 数据。Parquet: Parquet 是基于 Dremel 的数据模型和算法实现的,面向分析型业务的列式存储格式。它通过按列进行高效压缩和特殊的编码技术,从而在降低存储空间的同时提高了 IO 效率。
常用操作命令
常用DDL操作
查看数据列表: show databases;
使用数据库:USE database_name;
新建数据库:
1 | CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name --DATABASE|SCHEMA 是等价的 |
查看数据库信息:DESC DATABASE [EXTENDED] db_name; --EXTENDED 表示是否显示额外属性
删除数据库:
1 | -- 默认行为是 RESTRICT,如果数据库中存在表则删除失败。 |
创建表
1 | CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name --表名 |
支持从查询语句的结果创建表:
1 | CREATE TABLE emp_copy AS SELECT * FROM emp WHERE deptno='20'; |
修改表
重命名表:
1 | ALTER TABLE table_name RENAME TO new_table_name; |
修改列:
1 | ALTER TABLE table_name [PARTITION partition_spec] |
新增列:
1 | ALTER TABLE emp_temp ADD COLUMNS (address STRING COMMENT 'home address'); |
清空表/删除表
清空表:
1 | -- 清空整个表或表指定分区中的数据 |
目前只有内部表才能执行 TRUNCATE 操作,外部表执行时会抛出异常 Cannot truncate non-managed table XXXX
删除表:
1 | DROP TABLE [IF EXISTS] table_name [PURGE]; |
- 内部表:不仅会删除表的元数据,同时会删除 HDFS 上的数据;
- 外部表:只会删除表的元数据,不会删除 HDFS 上的数据;
- 删除视图引用的表时,不会给出警告(但视图已经无效了,必须由用户删除或重新创建)
其他
查看视图列表:
1 | SHOW VIEWS [IN/FROM database_name] [LIKE 'pattern_with_wildcards']; --仅支持 Hive 2.2.0 + |
查看表的分区列表:
1 | SHOW PARTITIONS table_name; |
查看表/视图的创建语句:
1 | SHOW CREATE TABLE ([db_name.]table_name|view_name); |
常用DML操作
和关系型数据库类似,具体参考: LanguageManual DML
排序关键字
sort by:不是全局排序,其在数据进入reducer前完成排序order by:会对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序).只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。distribute by:按照指定的字段对数据进行划分输出到不同的reduce中cluster by: 当distribute by 和sort by的字段相同时,等同于cluster by.可以看做特殊的distribute + sort
Hive中追加导入数据方式
从本地导入:
load data local inpath ‘/home/1.txt’ (overwrite)into table student;从HDFS导入:
load data inpath ‘/user/hive/warehouse/1.txt’ (overwrite)into table student;查询导入:
create table student1 as select * from student;(也可以具体查询某项数据)查询结果导入:
insert (overwrite)into table staff select * from track_log;
Hive导出数据方式
用insert overwrite导出方式
1.导出到本地:1
insert overwrite local directory ‘/home/robot/1/2’ rom format delimited fields terminated by ‘\t’ select * from staff;
2.导出到HDFS
1
insert overwrite directory ‘/user/hive/1/2’ rom format delimited fields terminated by ‘\t’ select * from staff;
Bash shell覆盖追加导出
1
$ bin/hive -e “select * from staff;” > /home/z/backup.log
sqoop把hive数据导出到外部