Hadoop系列-MapReduce
MapReduce的主要思想:自动将一个大的计算程序拆分成Map(映射)和Reduce(化简), 分冶思想
流程概括
input –> map –> shuffle –>reduce —>output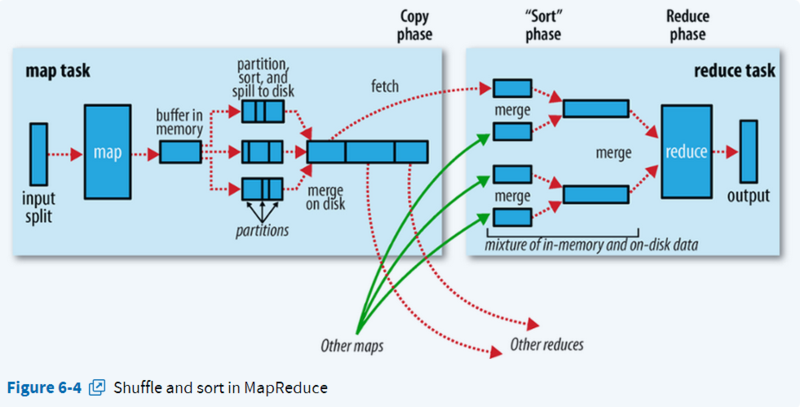
Map端流程
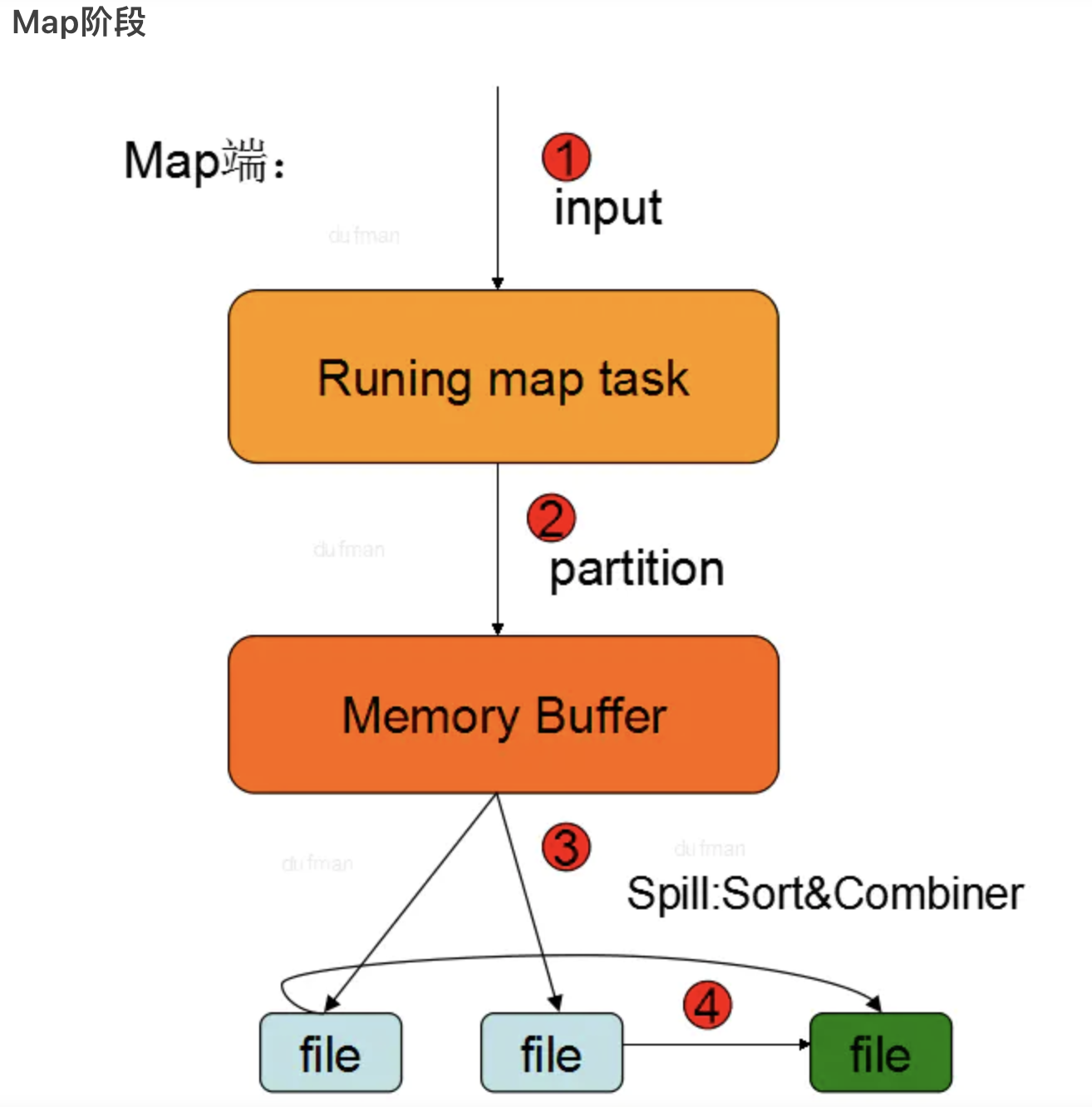
- Map: 自定义Map函数处理数据
- Partition: 为了将map的结果发送到相应的reduce端. 总的partition的数目等于reducer的数量. 具体实现为: 对key进行hash后,再以reduce task数量取模,然后到指定的job上(默认HashPartitioner,可以通过
job.setPartitionerClass(MyPartition.class)自定义) - Sort: 先按
<key,value,partition>中的partition分区号排序,然后再按key排序,这个就是sort操作,最后溢出的小文件是分区的,且同一个分区内是保证key有序的 - Combine: 提前进行统计,进行局部合并,减少Map端到Reduce端的数据传输消耗。要求开发者必须在程序中设置了combine(程序中通过
job.setCombinerClass(myCombine.class)自定义combine操作). 在两个阶段可能会发生: (1) map输出数据根据分区排序完成后,在写入文件之前会执行一次combine操作,当然前提是作业中设置了这个操作(2)如果map输出比较大,溢出文件个数大于3(此值可以通过属性min.num.spills.for.combine配置)时,在merge的过程中还会执行combine操作. - Merge: 当 map 很大时, 每次溢写会产生一个spill_file,这样会有多个spill_file, 这个时候就需要进行merge合并操作, 最终一个 MapTask只输出一个文件. 也即是,待Map Task任务的所有数据都处理完后,会对任务产生的所有中间数据文件做一次合并操作,以确保一个Map Task最终只生成一个中间数据文件
Reduce端流程
Copy: Reducer节点向各个mapper节点下载属于自己分区的数据,相同Partition的数据会落到同一节点
Merge:Reducer将不同Mapper节点上拉取的数据进行合并成一个文件
Reduce: 对数据进行统计
提交MR作业到Yarn流程
- 产生RunJar进程,客户端向RM申请执行一个job
- RM返回job相关的资源提交的路径staging-dir和本job产生的job ID
- 客户端会将job相关资源提交到相应的共享文件系统的路径下(/yarn-staging/jobID)
- 客户端向RM汇报提交结果
- RM将job加入任务队列
- NM通过与RM的心跳连接,从RM的任务队列中获取新的任务
- RM 向 NM 分配运行资源容器container
- RM在容器中启用 MRAppMaster 进程
- 由创建的 MRAppmaster 负责分配在哪些NodeManager上运行map(即yarnchild进程)和reduce任务
- 运行map和reduce任务的NM从共享文件系统中获取job相关资源,包括jar文件,配置文件等。然后运行map和reduce任务
- job执行完成后, MRAppMaster向RM注销自己,释放资源
Shuffle机制
从Map输出到Reduce输入的整个过程可以广义的称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包括Partition分区和Spill分割过程,在Reduce 端包括copy复制和Merge过程。
环形内存缓冲区
在map方法()中,最后一步通过OutputCollector.collect(key,value)或context.write(key,value)输出中间处理结果,在相关的collect(key,value)方法中,会调用Partitioner.getPartition(K2 key, V2 value, int numPartitions)方法获得输出的key/value对应的分区号(分区号可以认为对应着一个要执行Reduce Task的节点),然后将<key,value,partition>暂时保存在内存中的MapOutputBuffer内部的环形数据缓冲区,该缓冲区的默认大小是100MB,可以通过参数io.sort.mb来调整其大小
MapOutputBuffer内部存数的数据采用了两个索引结构,涉及三个环形内存缓冲区:
kvoffsets缓冲区:也叫偏移量索引数组,用于保存key/value信息在位置索引 kvindices 中的偏移量。当kvoffsets的使用率超过mapreduce.map.sort.spill.percent (默认为80%)后,便会触发一次 SpillThread 线程的“溢写”操作,也就是开始一次 Spill 阶段的操作。kvindices缓冲区:也叫位置索引数组,用于保存 key/value 在数据缓冲区 kvbuffer 中的起始位置。kvbuffer即数据缓冲区:用于保存实际的 key/value 的值。默认情况下该缓冲区最多可以使用io.sort.mb的95%,当kvbuffer 使用率超过 mapreduce.map.sort.spill.percent (默认为80%)后,便会出发一次 SpillThread 线程的“溢写”操作,也就是开始一次 Spill 阶段的操作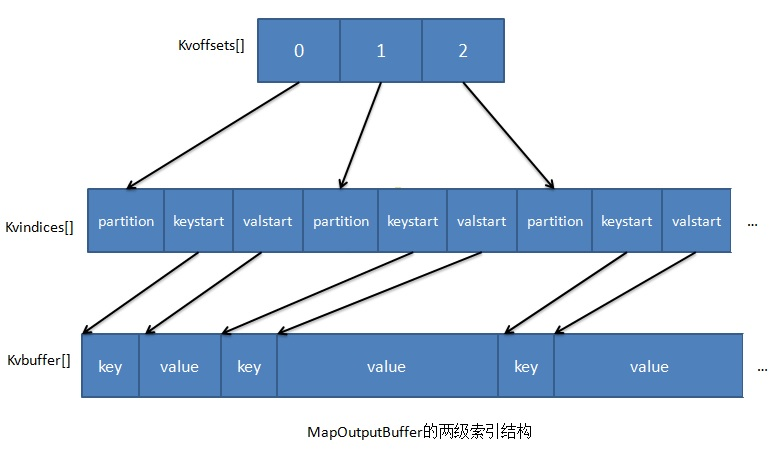
Spill溢写
当MapOutputBuffer内部的
kvoffsets缓冲区和kvbuffer即数据缓冲区达到阈值时触发进行spill操作。把内存缓冲区中的数据写入到本地磁盘,在写入本地磁盘时先按照partition、再按照key进行排序这个spill操作是由另外的单独线程来操作,不影响往缓冲区写map结果的线程
在将数据写入磁盘之前,先要对要写入磁盘的数据进行一次排序操作,先按<key,value,partition>中的partition分区号排序,然后再按key排序,这个就是sort操作,最后溢出的小文件是分区的,且同一个分区内是保证key有序的
Copy阶段
默认情况下,当整个MapReduce作业的所有已执行完成的Map Task任务数超过Map Task总数的5%后,JobTracker便会开始调度执行Reduce Task任务。然后Reduce Task任务默认启动mapred.reduce.parallel.copies(默认为5)个MapOutputCopier线程到已完成的Map Task任务节点上分别copy一份属于自己的数据。 这些copy的数据会首先保存的内存缓冲区中,当内存缓冲区的使用率达到一定阀值后,则写到磁盘上
补充
这个内存缓冲区大小的控制就不像map端的内存缓冲区那样通过io.sort.mb来设定了,而是通过另外一个参数来设置:mapred.job.shuffle.input.buffer.percent(default 0.7), 这个参数意思是:shuffile在reduce内存中的数据最多使用内存量为:0.7 × maxHeap of reduce task。如果该reduce task的最大heap使用量, 通常通过mapred.child.java.opts来设置,比如设置为-Xmx1024m,reduce会使用其heapsize的70%来在内存中缓存数据。如果reduce的heap由于业务原因调整的比较大,相应的缓存大小也会变大,这也是为什么reduce用来做缓存的参数是一个百分比,而不是一个固定的值了
Merge过程
Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比 map 端的更为灵活,它基于 JVM 的heap size设置,因为 Shuffle 阶段 Reducer 不运行,所以应该把绝大部分的内存都给 Shuffle 用
有三种形式:
内存到内存
内存到磁盘
磁盘到磁盘
默认情况下第一种形式是不启用的。当内存中的数据量到达一定阈值,就启动内存到磁盘的 merge(之所以进行merge是因为reduce端在从多个map端copy数据的时候,并没有进行sort,只是把它们加载到内存,当达到阈值写入磁盘时,需要进行merge)。这种merge方式一直在运行,直到没有 map 端的数据时才结束,然后才会启动第三种磁盘到磁盘的 merge 方式生成最终的文件